As I mentioned in my previous experiment, it has been a busy and difficult semester for me for family reasons. Accordingly, I am two and a half months behind schedule delivering my 12th and final experiment for this grant cycle. Additionally, I feel like my work for the past few months on this process has been a bit underwhelming, but unfortunately this work what my current bandwidth allows for. I hope to make up for it in the next year or so.
Anyway, the experiment for this month is similar to the one done for experiment 11. However, in this experiment I am generate vector images that reference maps of Boston’s subway system (the MBTA). Due to the complexity of the MBTA system I’ve created four different algorithms, reducing the visual data at any time to one quadrant of the map, thus, the individual programs are called: MBTA NW, MBTA NE, MBTA SE, & MBTA SW.
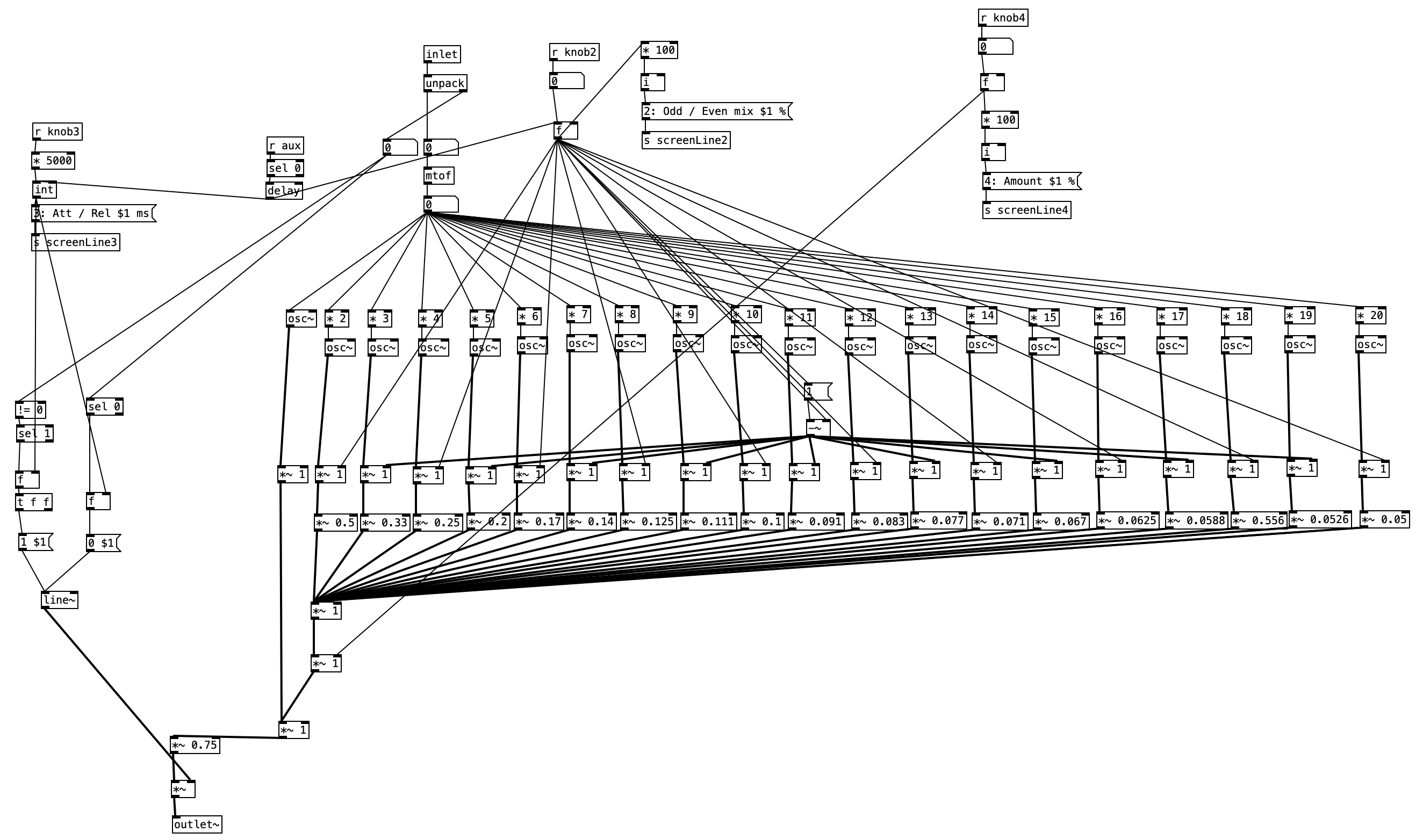
Since all four algorithms are basically the same, I’ll use MBTA – NE as an example. For each example Knob 5 was used for the background color. There were far more attributes I wanted to control than knobs I had at my disposal, so I decided to link them together. Thus, for MBTA – NE knob 1 controls red line attributes, knob 2 controls the blue and orange line attributes, knob 3 controls the green line attributes, and knob 4 controls the silver line attributes. Each of the four programs assigns the knobs to different combinations of colored lines based upon the complexity of the MBTA map in that quadrant.
The attributes that knobs 1-4 control include: line width, scale (amount of wiggle), color, and number of superimposed lines. The line width ranges from one to ten pixels, and is inversely proportional to the number of superimposed lines which ranges from on to eight. Thus, the more lines there are, the thinner they are. The scale, or amount of wiggle is proportional to the line width, that is the thicker the lines, the more they can wiggle. Finally, color is defined using RGB numbers. In each case, only one value (the red, the green, or the blue) changes with the knob values. The amount of change is a twenty point range centered around the optimal value. We can see this implemented below in the initialization portion of the program.
RElinewidth = int (1+(etc.knob1)*10)
BOlinewidth = int (1+(etc.knob2)*10)
GRlinewidth = int (1+(etc.knob3)*10)
SIlinewidth = int (1+(etc.knob4)*10)
etc.color_picker_bg(etc.knob5)
REscale=(55-(50*(etc.knob1)))
BOscale=(55-(50*(etc.knob2)))
GRscale=(55-(50*(etc.knob3)))
SIscale=(55-(50*(etc.knob4)))
thered=int (89+(10*(etc.knob1)))
redcolor=pygame.Color(thered,0,0)
theorange=int (40+(20*(etc.knob2)))
orangecolor=pygame.Color(99,theorange,0)
theblue=int (80+(20*(etc.knob2)))
bluecolor=pygame.Color(0,0,theblue)
thegreen=int (79+(20*(etc.knob3)))
greencolor=pygame.Color(0,thegreen,0)
thesilver=int (46+(20*(etc.knob4)))
silvercolor=pygame.Color(50,53,thesilver)
j=int (9-(1+(7*etc.knob1)))
The value j stands for the number of superimposed lines. This then transitions into the first of four loops, one for each of the groups of lines. Below we see the code for red line portion of program. The other three loops are fairly much the same, but are much longer due to the complexity of the MBTA map. An X and a Y coordinate are set inside this loop for every point that will be used. REscale is multiplied by a value from etc.audio_inwhich is divided by 33000 in order to change that audio level into a decimal ranging from 0 to 1 (more or less). This scales the value of REscale down to a smaller value, which is added to the numeric value. It is worth noting that because audio values can be negative, the numeric value is at the center of potential outcomes. Scaling the index number of etc.audio_in by (i*11), (i*11)+1, (i*11)+2, & (i*11)+3 lends a suitable variety of wiggles for each instance of a line.
j=int (9-(1+(7*etc.knob1)))
for i in range(j):
AX=int (320+(REscale*(etc.audio_in[(i*11)]/33000)))
AY=int (160+(REscale*(etc.audio_in[(i*11)+1]/33000)))
BX=int (860+(REscale*(etc.audio_in[(i*11)+2]/33000)))
BY=int (720+(REscale*(etc.audio_in[(i*11)+3]/33000)))
pygame.draw.line(screen, redcolor, (AX,AY), (BX, BY), RElinewidth)
I arbitrarily limited each program to 26 points (one for each letter of the alphabet). This really causes the vector graphic to be an abstraction of the MBTA map. The silver line in particular gets quite complicated, so I’m never really able to fully represent it. That being said, I think that anyone familiar with Boston’s subway system would recognize it if the similarity was pointed out to them. I also imagine any daily commuter on the MBTA would probably recognize the patterns in fairly short order. However, in watching my own video, which uses music generated by a PureData algorithm that will be used to write a track for my next album, I noticed that the green line in the MBTA – NE and MBTA – SW needs some correction.
The EYESY has been fully incorporated into my live performance routine as Darth Presley. You can see below a performance at the FriYay series at the New Bedford Art Museum. You’ll note that the projection is the Random Lines algorithm that I wrote. Likewise graduating senior Edison Roberts used the EYESY for his capstone performance as the band Geepers! You’ll see a photo of him below with a projection using the Random Concentric Circles algorithm that I wrote. I definitely have more ideas of how to use the EYESY in live performance. In fact, others have started to use ChatGPT to create EYESY algorithms.
Ultimately my work on this grant project has been fruitful. To date the algorithms I’ve written for the Organelle and EYESY have been circulated pretty well on Patchstorage.com (clearly the Organelle is the more popular format of the two) . . .
February was a very busy month for me for family reasons, and it’ll likely be that way for a few months. Accordingly, I’m a bit late on my February experiment, and will likely be equally late with my final experiment as well. I have also stuck with programming for the EYESY, as I have kind of been on a roll in terms of coming up with ideas for it.
This month I created twelve programs for the EYESY, each of which displays a different constellation from the zodiac. I’ve named the series Constellations and have uploaded them to patchstorage. Each one works in exactly the same manner, so we’ll only look at the simplest one, Aries. The more complicated programs simply have more points and lines in them with different coordinates and configurations, but are otherwise are identical.
Honestly, one of the most surprising challenges of this experiment way trying to figure out if there’s any consensus for a given constellation. Many of the constellations are fairly standardized, however others are fairly contested in terms of which stars are a part of the constellation. When there were variants to choose from I looked for consensus, but at times also took aesthetics into account. In particular I valued a balance between something that would look enticing and a reasonable number of points.
I printed images of each of the constellations, and traced them onto graph paper using a light box. I then wrote out the coordinates for each point, and then scaled them to fit in a 1280×720 resolution screen, offsetting the coordinates such that the image would be centered. These coordinates then formed the basis of the program.
import os
import pygame
import time
import random
import math
def setup(screen, etc):
pass
def draw(screen, etc):
linewidth = int (1+(etc.knob4)*10)
etc.color_picker_bg(etc.knob5)
offset=(280*etc.knob1)-140
scale=5+(140*(etc.knob3))
r = int (abs (100 * (etc.audio_in[0]/33000)))
g = int (abs (100 * (etc.audio_in[1]/33000)))
b = int (abs (100 * (etc.audio_in[2]/33000)))
if r>50:
rscale=-5
else:
rscale=5
if g>50:
gscale=-5
else:
gscale=5
if b>50:
bscale=-5
else:
bscale=5
j=int (1+(8*etc.knob2))
for i in range(j):
AX=int (offset+45+(scale*(etc.audio_in[(i*8)]/33000)))
AY=int (offset+45+(scale*(etc.audio_in[(i*8)+1]/33000)))
BX=int (offset+885+(scale*(etc.audio_in[(i*8)+2]/33000)))
BY=int (offset+325+(scale*(etc.audio_in[(i*8)+3]/33000)))
CX=int (offset+1165+(scale*(etc.audio_in[(i*8)+4]/33000)))
CY=int (offset+535+(scale*(etc.audio_in[(i*8)+5]/33000)))
DX=int (offset+1235+(scale*(etc.audio_in[(i*8)+6]/33000)))
DY=int (offset+675+(scale*(etc.audio_in[(i*8)+7]/33000)))
r = r+rscale
g = g+gscale
b = b+bscale
thecolor=pygame.Color(r,g,b)
pygame.draw.line(screen, thecolor, (AX,AY), (BX, BY), linewidth)
pygame.draw.line(screen, thecolor, (BX,BY), (CX, CY), linewidth)
pygame.draw.line(screen, thecolor, (CX,CY), (DX, DY), linewidth)
In these programs knob 1 is used to offset the image. Since only one offset is used, rotating the knob moves the image on a diagonal moving from upper left to lower right. The second knob is used to control the number of superimposed versions of the given constellation. The scale of how much the image can vary is controlled by knob 3. Knob 4 controls the line width, and the final knob controls the background color.
The new element in terms of programing is a for statement. Namely, I use for i in range (j) to create several superimposed versions of the same constellation. As previously stated, the amount of these is controlled by knob 2, using the code j=int (1+(8*etc.knob2)). This allows for anywhere from 1 to 8 superimposed images.
Inside this loop, each point is offset and scaled in relationship to audio data. We can see for any given point the value is added to the offset. Then the scale value is multiplied by data from etc.audio_in. Using different values within this array allows for each point in the constellation to react differently. Using the variable i within the array also allows for differences between the points in each of the superimposed versions. The variable scale is always set to be at least 5, allowing for some amount of wiggle given all circumstances.
Originally I had used data from etc.audio_in inside the loop to set the color of the lines. This resulted in drastically different colors for each of the superimposed constellations in a given frame. I decided to tone this down a bit, by using etc.audio_in data before the loop started allowing each version of the constellation within a given frame to be largely the same color. That being said, to create some visual interest, I use rscale, gscale, and bscale to move the color in a direction for each superimposed version. Since the maximum amount of superimposed images is 8, I used the value 5 to increment the red, green, and blue values of the color. When the original red, green, or blue value was less than 50 I used 5, which moves the value up in value. When the original red, green, or blue value was more than 50 I used -5, which moves the value down in value. The program chooses between 5 and -5 using if :else statements.
The music used in the example videos are algorithms that will be used to generate accompaniment for a third of my next major studio album. These algorithms grew directly out of my work on these experiments. I did add one little bit of code the these puredata algorithms however. Since I have 6 musical examples, but 12 EYESY patches, I added a bit of code that randomly chooses between 1 of 2 EYESY patches and sends out a program (patch) change to the EYESY on MIDI channel 16 at the beginning of each phrase.
While I may not use these algorithms for the videos for the next studio album, I will likely use them in live performances. I plan on doing a related set of EYESY programs for my final experiment next month.
I kind of hit a wall of the Organelle. I feel like in order to advance my skills I have a bit of a hurdle between where my programming skills are at, and where they would need to be to do something more advanced that the recent experiments I have completed. Accordingly for this month I decided to shift my focus to the EYESY. Last month I made significant progress in understanding Python programming for the EYESY, and that allowed me to come up with five ideas for algorithms in short order. The music for all five mini-experiments comes from PureData algorithms I will be using for my next major album. All five of these algorithms are somewhat derived from my work on my last album.
The two realizations that allowed me to make significant progress on EYESY programming is that Python is super picky about spaces, tabs, and indentations, and that while the EYESY usually gives little to no feedback when a program has an error in it, you can use an online Python compiler to help figure out where your error is (I had mentioned the latter in last month’s experiment). Individuals who have a decent amount of programming experience may scoff at the simplicity of the programs that follow, but for me it is a decent starting place, and it is also satisfying to me to see how such simple algorithms can generate such gratifying results.
Random Lines is a patch I wrote that draws 96 lines. In order to do this in an automated fashion, I have to use a loop, in this case I use for i in range(96):. The five lines that follow are all executed in this loop. Before the loop commences, we choose the color using knob 4 and the background color using knob 5. I use knob 3 to set the line width, but I scale it by multiplying the knob’s value, which will be between 0 and 1, by 10, and adding 1, as line widths cannot have a value of 0. I also have to cast the value as an integer. I set an x offset value using knob 1. Multiplying by 640 and then subtracting 320 will yield a result between -320 and 320. Likewise, a y offset value is set using knob 2, and the scaling results in a value between -180 and 180.
import os
import pygame
import time
import random
import math
def setup(screen, etc):
pass
def draw(screen, etc):
color = etc.color_picker(etc.knob4)
linewidth = int (1+ (etc.knob3)*10)
etc.color_picker_bg(etc.knob5)
xoffset=(640*etc.knob1)-320
yoffset=(360*etc.knob2)-180
for i in range(96):
x1 = int (640 + (xoffset+(etc.audio_in[i])/50))
y1 = int (360 + (yoffset+(etc.audio_in[(i+1)])/90))
x2 = int (640 + (xoffset+(etc.audio_in[(i+2)])/50))
y2 = int (360 + (yoffset+(etc.audio_in[(i+3)])/90))
pygame.draw.line(screen, color, (x1,y1), (x2, y2), linewidth)
Within the loop, I set two coordinates. The EYESY keeps track of the last hundred samples using etc.audio_in[]. Since these values use sixteen bit sound, and sound has peaks (represented by positive numbers) and valleys (represented by negative numbers), these values range between -32,768 and 32,787. I scale these values by dividing by 50 for x coordinates. This will scale the values to somewhere between -655 and 655. For y coordinates I divide by 90, which yields values between -364 and 364.
In both cases, I add these values to the corresponding offset value, and add the value that would normally, without the offsets, place the point in the middle of the screen, namely 640 (X) and 360 (Y). A negative value for the xoffset or the scaled etc.audio_in value would move that point to the left, while a positive value would move it to the right. Likewise, a negative value for the yoffset or the scale etc.audio_in value would move the point up, while a positive value would move it down.
Since subsequent index numbers are used for each coordinate (that is i, i+1, i+2, and i+3), this results in a bunch of interconnected lines. For instance when i=0, the end point of the drawn line (X2, Y2) would become the starting point when i=2. Thus, the lines are not fully random, as they are all interconnected, yielding a tangled mass of lines.
Random Concentric Circles uses a similar methodology. Again, knob five is use to control the background color, while knobs 1 and 2 are again scaled to provide an X and Y offset. The line width is shifted to knob 4. For this algorithm the loop happens 94 times. The X and Y value for the center of the circles is determined the same way as was done in Random Lines. However, we now need a radius and we need a color for each circle.
import os
import pygame
import time
import random
import math
def setup(screen, etc):
pass
def draw(screen, etc):
linewidth = int (1+(etc.knob4)*9)
etc.color_picker_bg(etc.knob5)
xoffset=(640*etc.knob1)-320
yoffset=(360*etc.knob2)-180
for i in range(94):
x = int (640 + xoffset+(etc.audio_in[i])/50)
y = int (360 + yoffset+(etc.audio_in[(i+1)])/90)
radius = int (11+(abs (etc.knob3 * (etc.audio_in[(i+2)])/90)))
r = int (abs (100 * (etc.audio_in[(i+3)]/33000)))
g = int (abs (100 * (etc.audio_in[(i+4)]/33000)))
b = int (abs (100 * (etc.audio_in[(i+5)]/33000)))
thecolor=pygame.Color(r,g,b)
pygame.draw.circle(screen, thecolor, (x,y), radius, linewidth)
We have knob 3 available to help control the radius of the circle. Here I multiply knob 3 by a scaled version of etc.audio_in[(i+2)]. I scale it by dividing by 90 so that the largest possible circle will mostly fit on the screen if it is centered in the screen. Notice that when we multiply knob 3 by etc.audio_in, there’s a 50% chance that the result will be a negative number. Negative values for radii don’t make any sense, so I take the absolute value of this outcome using abs. I also add this value to 11, as a radius of 0 makes no sense, and a radius of less than 10, as having a line width that is larger than the radius will cause an error.
For this algorithm I take a set forward by giving each circle its own color. In order to do this I have to set the value for red, green, and blue separately, and then combine them together using pygame.Color(). For each of the three values (red, green, and blue) I divide a value of etc. audio_in by 33000, which will yield a value between 0 and 1 (more or less), and then multiply this by 100. I could have done the same thing by simply dividing etc.audio_in by 330, however, at the time this process made the most sense to me. Again, this process could result in a negative number and / or a fractional value, so I cast the result as an integer after getting its absolute value.
Colored Rectangles has a different structure than the previous two examples. Rather than have all the objects cluster around a center point I wanted to create an algorithm that spaces all of the objects out evenly throughout the screen in a grid like pattern. I do this using an eight by eight grid of 64 rectangles. I accomplish the spacing using modulus mathematics as well as integer division. The X value is obtained by multiplying 160 times i%8. In a similar vein, the Y values is set to 90 times i//8. Integer division in Python is accomplished through the use of two slashes. Using this operator will return the integer value of a division problem, omitting the fractional portion. Both the X and the Y values have an additional offset value. The X is offset by (i//8)*(80*etc.knob1), so this offset increases as knob 1 is turned up, with a maximum offset of 80 pixels per row. The value i//8 essentially multiplies that offset by the row number. That is the rows shift further towards the right.
import os
import pygame
import time
import random
import math
def setup(screen, etc):
pass
def draw(screen, etc):
etc.color_picker_bg(etc.knob5)
for i in range(64):
x=(i%8)*160+(i//8)*(80*etc.knob1)
y=(i//8)*90+(i%8)*(45*etc.knob2)
thewidth=int (abs (160 * (etc.knob3) * (etc.audio_in[(i)]/33000)))
theheight=int (abs (90 * (etc.knob4) * (etc.audio_in[(i+1)]/33000)))
therectangle=pygame.Rect(x,y,thewidth,theheight)
r = int (abs (100 * (etc.audio_in[(i+2)]/33000)))
g = int (abs (100 * (etc.audio_in[(i+3)]/33000)))
b = int (abs (100 * (etc.audio_in[(i+4)]/33000)))
thecolor=pygame.Color(r,g,b)
pygame.draw.rect(screen, thecolor, therectangle, 0)
Likewise, the Y offset is determined by (i%8)*(45*etc.knob2). As the value of knob 2 increases, the offset moves towards a maximum value of 45. However, as the columns shift to the right, those offsets compound due to the fact that they are multiplied by (i%8).
A rectangle can be defined in pygame by passing an X value, a Y value, width, and height to pygame.Rect. Thus, the next step is to set the width and height of the rectangle. In both cases, I set the maximum value to 160 (for width) and 90 (for height). However, I scaled them both by multiplying by a knob value (knob 3 for width and knob 4 for height). These values are also scaled by an audio value divided by 33,000. Since negative values are possible from audio values, and negative widths and heights don’t make much sense, I took the absolute value of each. If I were to rewrite this algorithm (perhaps I will), I would set a minimum value for width and height such that widths and heights of 0 were not possible.
I set the color of each rectangle using the same method as I did in Random Concentric Circles. In order to draw the rectangle you pass the screen, the color, the rectangle (as defined by pygame.Rect), as well as the line width to pygame.draw.rect. Using a line width of 0 means that the rectangle will be filled in with color.
Random Rectangles is a combination of Colored Rectangles and Random Lines. Rather than use pygame’s Rect object to draw rectangles on the screen, I use individual lines to draw the rectangles (technically speaking they are quadrilaterals). Knob 4 is used here to set the foreground color, knob 5 is used here to set the background color, knob 3 is used to set the linewidth.
import os
import pygame
import time
import random
import math
def setup(screen, etc):
pass
def draw(screen, etc):
color = etc.color_picker(etc.knob4)
etc.color_picker_bg(etc.knob5)
linewidth = int (1+ (etc.knob3)*10)
for i in range(64):
x=(i%8)*160+(i//8)*(80*etc.knob1)+(40*(etc.audio_in[(i)]/33000))
y=(i//8)*90+(i%8)*(45*etc.knob2)+(20*(etc.audio_in[(i+1)]/33000))
x1=x+160+(40*(etc.audio_in[(i+2)]/33000))
y1=y+(20*(etc.audio_in[(i+3)]/33000))
x2=x1+(40*(etc.audio_in[(i+4)]/33000))
y2=y1+90+(20*(etc.audio_in[(i+5)]/33000))
x3=x+(40*(etc.audio_in[(i+6)]/33000))
y3=y+90+(20*(etc.audio_in[(i+7)]/33000))
pygame.draw.line(screen, color, (x,y), (x1, y1), linewidth)
pygame.draw.line(screen, color, (x1,y1), (x2, y2), linewidth)
pygame.draw.line(screen, color, (x2,y2), (x3, y3), linewidth)
pygame.draw.line(screen, color, (x3,y3), (x, y), linewidth)
Within the loop, I use a similar method of setting the initial X and Y coordinates. That being said, I separate out the use of knobs and the use of audio input. In the case of the X coordinated, I use (i//8)*(80*etc.knob1) to control the amount of x offset for each row, with a maximum offset of 80. The audio input then offsets this value further using (40*etc.audio_in[(i+2)]/33000). This moves the x value by a value of plus or minus 40 (remember that audio values can be negative. Likewise, knob 2 offsets the Y value for every row by a maximum of 45, and the audio input further offsets this value by plus or minus 20.
Since it takes four points to define a quadrilateral, we need three more points, which we will call (x1, y1), (x2, y2), and (x3, y3). These are all interrelated. The value of X is used to define X1 and X3, while X2 is based off of X1. Likewise, the value of Y helps define Y1 and Y3, with Y2 being based off of Y1. In the case X1 and X2 (which is based on X1) we add 160 to X, giving a default width, but these values are again scaled by etc.audio_in. Similarly, we add 90 to Y1 and Y3 to determine a default height of the quadrilaterals, but again, all points are further offset by etc.audio_in, resulting in quadrilaterals, rather than rectangles with parallel sides. If I were to revise this algorithm I would likely make each quadrilateral a different color.
Frankly, I was not as pleased with the results of Colored Rectangles and Random Rectangles, so I decided to go back create an algorithm that was an amalgam of Random Lines and Random Concentric Circles, namely Random Radii. This program creates 95 lines, all of which have the same starting point, but different end points. Knob 5 sets the background color, while knob 4 sets the line width.
import os
import pygame
import time
import random
import math
def setup(screen, etc):
pass
def draw(screen, etc):
linewidth = int (1+ (etc.knob4)*10)
etc.color_picker_bg(etc.knob5)
xoffset=(640*etc.knob1)-320
yoffset=(360*etc.knob2)-180
X=int (640+xoffset)
Y=int (360+yoffset)
for i in range(95):
r = int (abs (100 * (etc.audio_in[(i+2)]/33000)))
g = int (abs (100 * (etc.audio_in[(i+3)]/33000)))
b = int (abs (100 * (etc.audio_in[(i+4)]/33000)))
thecolor=pygame.Color(r,g,b)
x2 = int (640 + (xoffset+etc.knob3*(etc.audio_in[(i)])/50))
y2 = int (360 + (yoffset+etc.knob3*(etc.audio_in[(i+1)])/90))
pygame.draw.line(screen, thecolor, (X,Y), (x2, y2), linewidth)
Knob 1 & 2 are used for X and Y offsets (respectively) of the center point. Using (640*etc.knob1)-320 means that the X value will move plus or minus 320. Similarly, (360*etc.knob2)-180 permits the Y value to move up or down by 180. As is the case with Random Concentric Circles, the color of each line is defined by etc.audio_in. Knob 3 is used to scale the end point of each line. In the case of both the X and Y values, we start from the center of the screen (640, 360) add the offset defined by knobs 1 or 2, and then use knob 3 to scale a value derived from etc.audio_in. Since audio values can be positive or negative, these radii shoot outward from the offset center point in all directions.
As suggested earlier, I am very gratified with these results. Despite the simplicity of the Python code, the results are mostly dynamic and compelling (although I am somewhat less than thrilled with Colored Rectangles and Random Rectangles). The user community for the EYESY is much smaller than that of the Organelle. The EYESY user’s forum has only 13% the activity of that of the Organelle. I seem to have inherited being the administrator of the ETC / EYESY Video Synthesizer from Critter&Guitari group on Facebook. Likewise, I am the author of the seven most recent patches for the EYESY on patchstorage. Thus, this month’s experiment sees me shooting to the top to become the EYESY’s most active developer. The start of the semester has been very busy for me. I am somewhat doubting that I will be coming up with an Organelle patch next month, but I equally suspect that I will continue to develop more algorithms of the EYESY.
This month’s experiment is a considerable step forward on three fronts: Organelle programming, EYESY programming, and computer assisted composition. In terms of Organelle programming, rather than taking a pre-existing algorithm and altering it (or hacking it) to do something different, I decided to create a patch from scratch. I first created it in PureData, and then reprogrammed it to work specifically with the Organelle. Creating it in PureData first meant that I used horizontal sliders to represent the knobs, and that I sent the output to the DAC (digital to analog converter). When coding for the Organelle, you use a throw~ object to output the audio.
The patch I wrote, Wavetable Sampler, reimagines a digital sampler, and in doing so, basically reinvents wavetable synthesis. The conventional approach to sampling is to travel through the sound in a linear fashion from beginning to end. The speed at which we travel through the sound determines both its length and its pitch, that is faster translates to shorter and higher pitched, while slower means longer and lower pitched.
I wanted to try using an LFO (low frequency oscillator) to control where we are in a given sample. Using this technique the sound would go back and forth between two points in the sample continuously. In my programming I quickly learned that two parameters are strongly linked, namely the frequency of this oscillator and the amplitude of the oscillator, which becomes the distance travelled in the sample. If you want the sample to be played at a normal speed, that is we recognize the original sample, those two values need to be proportional. To describe this simply, a low frequency would require the sample to travel farther while a higher frequency would need a small amount of space. Thus, we see the object expr (44100 / ($f1)), with the number 44,100 being the sample rate of the Organelle. Dividing the sample rate by the frequency of the oscillator yields the number of samples that make up a cycle of sound at that frequency.
Obviously, a user might want to specifically move at a different rate than what would be normal. However, making that a separate control prevents the user from having to mentally calculate what would be an appropriate sample increment to have the sample play back at normal speed. I also specified that a user will want to control where we are in a much longer sample. For instance, the sample I am using with this instrument is quite long. It is an electronic cello improvisation I did recently that lasts over four minutes.
The sound I got out of this instrument was largely what I expected. However, there was one aspect that stood out more than I thought it would. I am using a sine wave oscillator in the patch. This means that the sound travels quickly during the rise and fall portion of the waveform, but as it approaches the peak and trough of the waveform it slows down quite dramatically. At low frequencies this results in extreme pitch changes. I could easily have solved this issue by switching to a triangle waveform, as speed would be constant using such a waveform. However, I decided that the oddness of these pitch changes were the feature of the patch, and not the bug.
While I intended the instrument to be used at low frequencies, I found that it was actually far more practical and conventionally useful at audio frequencies. Human hearing starts around 20Hz, which means if you were able to clap your hands 20 times in a second you would begin to hear it as a very low pitch rather than a series of individual claps. One peculiarity of sound synthesis is that if you repeat a series of samples, no mater how random they may be, at a frequency that lies within human hearing, you will hear it as a pitch that has that frequency. The timbre between two different sets of samples at the same frequency may vary greatly, but we will hear them as being, more or less, the same pitch.
Thus, as we move the frequency of the oscillator up into the audio range, it turns into somewhat of a wavetable synthesizer. While wavetable synthesis was created in 1958, it didn’t really exist in its full form until 1979. At this point in the history of synthesis it was an alternative to FM synthesis, which could offer robust sound possibilities but was very difficult to program, and digital sampling, which could recreate any sound that could be recorded but was extremely expensive due to the cost of memory. In this sense wavetable synthesis is a data saving tool. If you imagine a ten second recording of a piano key being struck and held, the timbre of that sound changes dramatically over those ten seconds, but ten seconds of sampling time in 1980 was very expensive. Imagine if instead we can digitize individual waveforms at five different locations in the ten second sample, we can then gradually interpolate between those five waveforms to create a believable (in 1980) approximation of the original sample. That being said, wavetable synthesis also created a rich, interesting approach to synthesizing new sounds such that the technique is still somewhat commonly used today.
When we move the oscillator for Wavetable Sampler into the audio range, we are essentially creating a wavetable. The parameter that effects how far the oscillator travels through the sample creates a very interesting phenomenon at audio rates. When that value is very low, the sample values vary very little. This results in waveforms that approach a sine wave in their simplicity and spectrum. As this value increases more values are included, which may differ greatly from each other. This translates into adding harmonics into the spectrum. Which harmonics are added are dependent up the wavetable, or snippet of a sample, in question. However, as we turn up the value, it tends to add harmonics from lower ones to higher ones. At extreme values, in this case ten times a normal sample increment, the pitch of the fundamental frequency starts to be over taken by the predominant frequencies in that wavetable’s spectrum. One final element of interest with the construction of the instrument in relation to wavetable synthesis is related to the use of a sine wave for the oscillator. Since the rate of change speeds up during the rise and fall portion of the waveform and slows down near the peak and the valley of the wave, that means there are portions of the waveform that rich in change while other portions where the rate of change is slow.
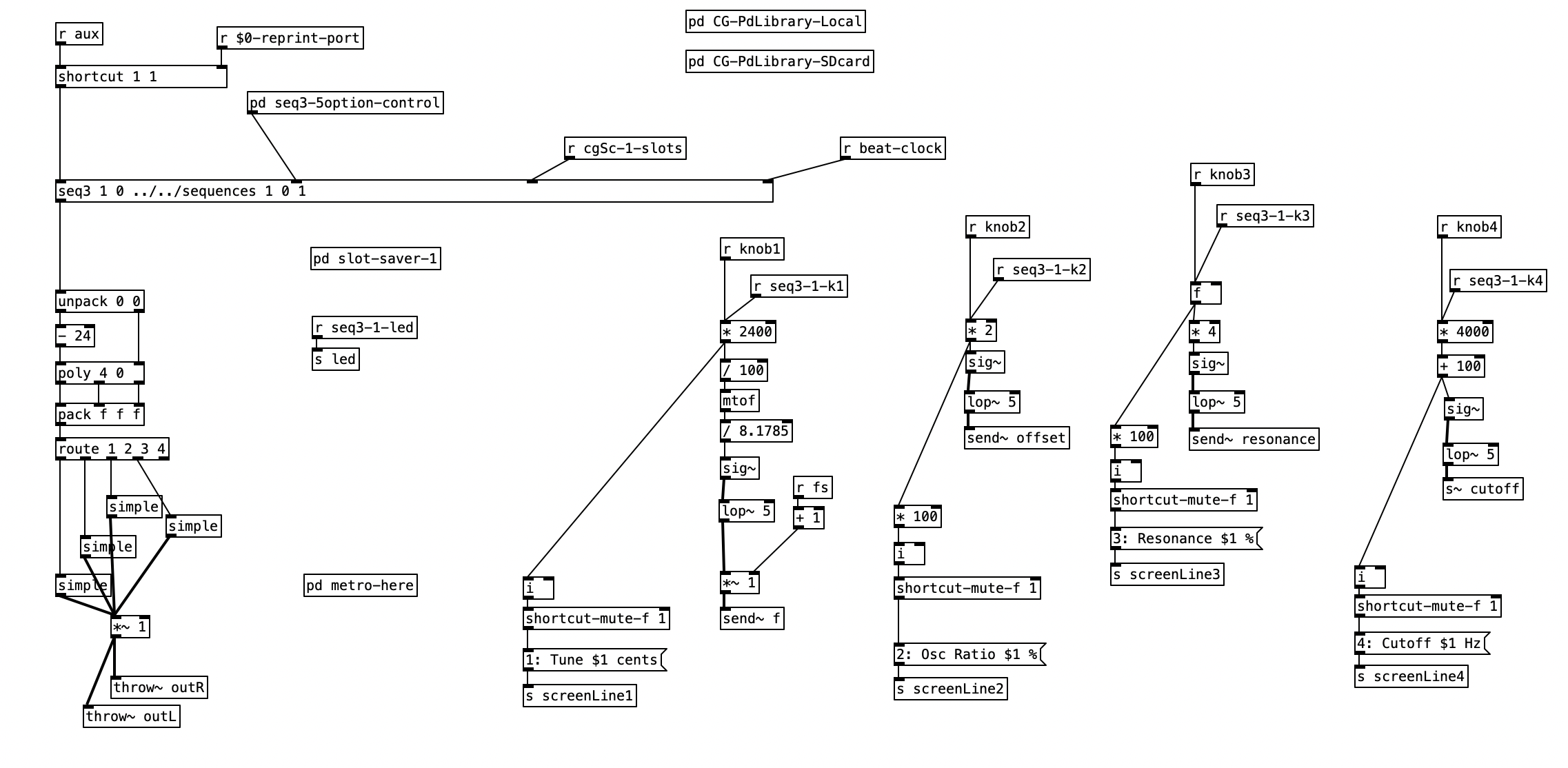
Since the value that the oscillator travels seems to be analogous to increasing the harmonic spectrum, I decided to put that on knob four, as that is the knob I have been controlling via breath pressure with the WARBL. On the Organelle I set knob one to set the index of where we are in the four minute plus sample. The frequency of the oscillator is set by the key that is played, but I use the second knob as a multiplier of this value. This knob is scaled from .001, which will yield a true low frequency oscillator, to 1, which will be at the pitch played (.5 will be down an octave, .25 will be down two octaves, etc.). As stated earlier, the fourth knob is used to modify the amplitude of the oscillator, affecting the range of samples that will be cycled through. This left the third knob unused, so I decided to use that as a decay setting.
The PureData patch that was used to generate the accompaniment for this experiment was based upon the patch created for last month’s experiment. As a reminder, this algorithm randomly chooses between one of four musical meters, 4/4, 3/4, 7/8, and 5/8, at every new phrase. I altered this algorithm to fit a plan I have for six of the tracks on my next studio album, which will likely take three or four years to complete. Rather than randomly selecting them, I define an array of numbers that represent the meters that should be used in the order that they appear. At every phrase change I then move to the next value in the array, allowing the meters to change in a predetermined fashion.
I put the piece of magic that allows this to happen in pd phrasechange. The inlet to this subroutine goes to a sel statement that contains the numbers of new phrase numbers expressed in sixteenth notes. When those values are reached a counter is incremented, a value from the table meter is read, which is sent to the variable currentmeter and the phrase is reset. This subroutine has four outlets. The first starts a blinking light that indicates that the piece is 1/3 finished, the second outlet starts a blinking light that starts when the piece is 2/3 of the way finished. The third outlet starts a blinking light that indicates the piece is on its final phrase. The fourth outlet stops the algorithm, bringing a piece to a close. Those blinking lights are on the right hand side of the screen, located near the buttons that indicate the current meter and the current beat. A performer can then, with some practice watch the computer screen to see what the current meter is, what the current beat is, and to have an idea of where you are in form of the piece.
This month I created my first program for the EYESY, Basic Circles. The EYESY manual includes a very simple example of a program. However, it is too simple it just displays a circle. The circle doesn’t move, none of the knobs change anything, and the circle isn’t even centered. With very little work I was able to center the circle, and change it so that the size of the circle was controlled by the volume of the audio. Likewise, I was able to get knob four to control the color of the circle, and the fifth knob to control the background color.
However, I wanted to create a program that used all five knobs on the EYESY. I quickly came up with the idea of using knob two to control the horizontal positioning, and the third knob to control the vertical positioning. I still had one knob left, and only a simple circle in the middle of the screen to show for it. I decided to add a second circle, that was half the size of the first one. I used knob five to set the color for this second circle, although oddly it does not result in the same color as the background. Yet, this still was not quite visually satisfying, so I set knob one to set an offset from the larger circle. Accordingly, when knob one is in the center, the small circle is centered within the larger one. As you turn the knob to the left the small circle moves to the upper left quadrant of the screen. As you turn the knob to the right the smaller circle moves towards the lower right quadrant. This is simple, but offers just enough visual interest to be tolerable.
import os
import pygame
import time
import random
import math
def setup(screen, etc):
pass
def draw(screen, etc):
size = (int (abs (etc.audio_in[0])/100))
size2 = (int (size/2))
position = (640, 360)
color = etc.color_picker(etc.knob4)
color2 = etc.color_picker(etc.knob5)
X=(int (320+(640*etc.knob2)))
X2=(int (X+160-(310*etc.knob1)))
Y=(int (180+(360*etc.knob3)))
Y2=(int (Y+90-(180*etc.knob1)))
etc.color_picker_bg(etc.knob5)
pygame.draw.circle(screen, color, (X,Y), size, 0)
pygame.draw.circle(screen, color2, (X2,Y2), size2, 0)
While the program, listed above, is very simple, it was my first time programming in Python. Furthermore, targeting the EYESY is not the simplest thing to do. You have plug a wireless USB adapter into the EYESY, connect to the EYESY via a web browser, upload your program as a zip file, unzip the file, and then delete the zip file. You then have to restart the video on the EYESY to see if the patch works. If there is an error in your code, the program won’t load, which means you cannot trouble shoot it, you just have to look through your code line by line and figure it out. Although, I learned to use an online Python compiler to check for basic errors. If you have a minor error in your code the EYESY will sometimes load the program and display a simple error message onscreen, which will allow you to at least figure where the error is.
I’m very pleased with the backing track, and given that it is my first program for the EYESY, with the visuals. I’m not super pleased with the audio from the Organelle. Some of this is due to my playing. For this experiment I used a very limited set of pitches in my improvisation, which made the fingering easier than it has been in other experiments. Also, I printed out a fingering chart and kept it in view as I played. Part of it is due to my lack of rhythmic accuracy. I am still getting used to watching the screen in PureData to see what meter I am in and what the current beat is. I’m sure I’ll get the hang of it with some practice.
One fair question to ask is do I continue to use the WARBL to control the Organelle if I consistently find it so challenging? The simple answer is that consider a wind controller to be the true test of the expressiveness of a digital musical instrument. I should be able to make minute changes to the sound by slight changes in breath pressure. After working with the Organelle for nine months, I can say that it fails this test. The knobs on the Organelle seem to quantize at a low resolution. As you turn a knob you are changing the resistance in a circuit. The resulting current is then quantized, that is its absolute value is rounded to the nearest digital value. I have a feeling that the knobs on the Organelle quantize to seven bits in order to directly correspond to MIDI, which is largely a seven bit protocol. Seven bits of data only allow for 128 possible values. Thus, we hear discrete changes rather than continual ones as we rotate a knob. For some reason I find this short coming is amplified rather than softened when you control the Organelle with a wind controller. At some point I should do a comparison where I control a PureData patch on my laptop using the WARBL without using the Organelle.
I recorded this experiment using multichannel recording, and I discovered something else that is disappointing about the Organelle. I found that there was enough background noise coming from the Organelle that I had to use a noise gate to clean up the audio a bit. In fact, I had to set the threshold at around -35 dB to get rid of the noise. This is actually pretty loud. The Volca Keys also requires a noise gate, but a lower threshold of -50 or -45 dB usually does the trick with it.
Perhaps this noise is due to a slight ground loop, a small short in the cable, RF interference, or some other problem that does not originate in the Organelle, but it doesn’t bode well. Next month I may try another FM or additive instrument. I do certainly have a good head start on the EYESY patch for next month.
I’m afraid I’m not as pleased with this month’s entry as I had hoped to be. The instrument I developed worked fairly well on the Organelle, but when I used it in combination with a wind controller, it was not nearly as expressive as I had hoped. I had also hoped to use the EYESY with a webcam, but I was not able to get the EYESY to recognize either of my two USB webcams. That being said, I think the instrument I designed is a good starting point for further development.
The instrument I designed, Additive Odd Even, is an eight-voice additive synthesizer. Additive synthesis, as the name implies, is an alternative approach to subtractive synthesis. Subtractive synthesis was the most common approach for the first decades of synthesis, as it requires the fewest / least expensive components in comparison to most other approaches. Subtractive synthesis involves taking periodic waveforms that have rich harmonic content, and using filters to subtract some of that content to create new sounds.
Additive synthesis was theorized by rarely attempted since the beginning of sound synthesis. Technically speaking the early behemoth, the Teleharmonium, used additive synthesis. Likewise, earlier electronic organs often used some variant of additive synthesis. One of the few true early additive synthesizers was the Harmonic Tone Generator. However, this instrument’s creator, James Beauchamp only made two of them.
Regardless, additive synthesis involves adding pure sine tones together to create more complex waveforms. In typical early synthesizers, this was impractical, as it would require numerous expensive oscillators in order to accomplish this approach. As a point of reference, the Harmonic Tone Generator only used six partials.
Additive Odd Even is based upon Polyphonic Additive Synth by user wet-noodle. In my patch, knob one controls the transposition level, allowing the user to raise or lower the pitch chromatically up to two octaves in either direction. The second knob controls the balance of odd versus even partials. When this knob is in the middle, the user will get a sawtooth wave, and when it is turned all the way to the left, a square wave will result. Knob three controls both the attack and release, which are defined in terms of milliseconds, ranging from 0 to 5 seconds. The final knob controls the amount of additive synthesis applied, yielding a multiplication value of 0 to 1. This last knob is the one that is controlled by the amount of breath pressure from the WARBL. Thus, in theory, as more breath pressure is supplied, we should hear more overtones.
This instrument consists only of a main routine (main.pd) and one abstraction (voice.pd). Knob one is controlled in the main routine, while the rest exist in the abstraction. As we can see below, voice.pd contains 20 oscillators, which in turn provide 20 harmonic partials for the sound. We can see this in the way in which the frequency of each successive oscillator is multiplied by integers 1 through 20. A bit below these oscillators, we see that the amplitudes of these oscillators is multiplied by successively smaller values from 1 down to .05. These values roughly correspond to 1/n, where n is the harmonic value. Summing these values together would result in a sawtooth waveform.
We see more multiplication / scaling above these values. Half of them come directly from knob 2, which controls the odd / even mix. These are used to scale only the even numbered partials. Thus, when the second knob is turned all the way to the left, the result is 0, which effectively turns off all the even partials. This results in only the odd partials being passed through, yielding a square waveform. The odd numbered partials are scaled using 1 minus the value from the second knob. Accordingly, when knob 2 is placed in the center position, the balance between the odd and even partials should be the same, yielding a sawtooth wave. Once all but the fundamental is scaled by knobs 2 & 4, they are mixed together, and mixed with the fundamental. Thus, we can see that neither knob 2 nor 4 affects the amplitude of thefundamental partial. This waveform is then scaled by .75 to avoid distortion, and then scaled by the envelope, provided by knob three.
In August I had about one month of data loss. Accordingly, I lost much of the work I did on the PureData file that I used to generate the accompaniment for Experiment 5. Fortunately I had the blog entry for that experiment to help me reconstruct that program. I also added a third meter, 7/8, in addition to the two meters used in Experiment 5 (4/4 and 3/4). Most of the work to add this is adding a bunch of arrays, and continuing the expansion of the algorithm that was already covered in the blog entry for Experiment 5.
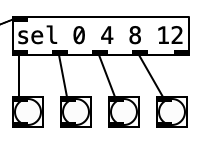
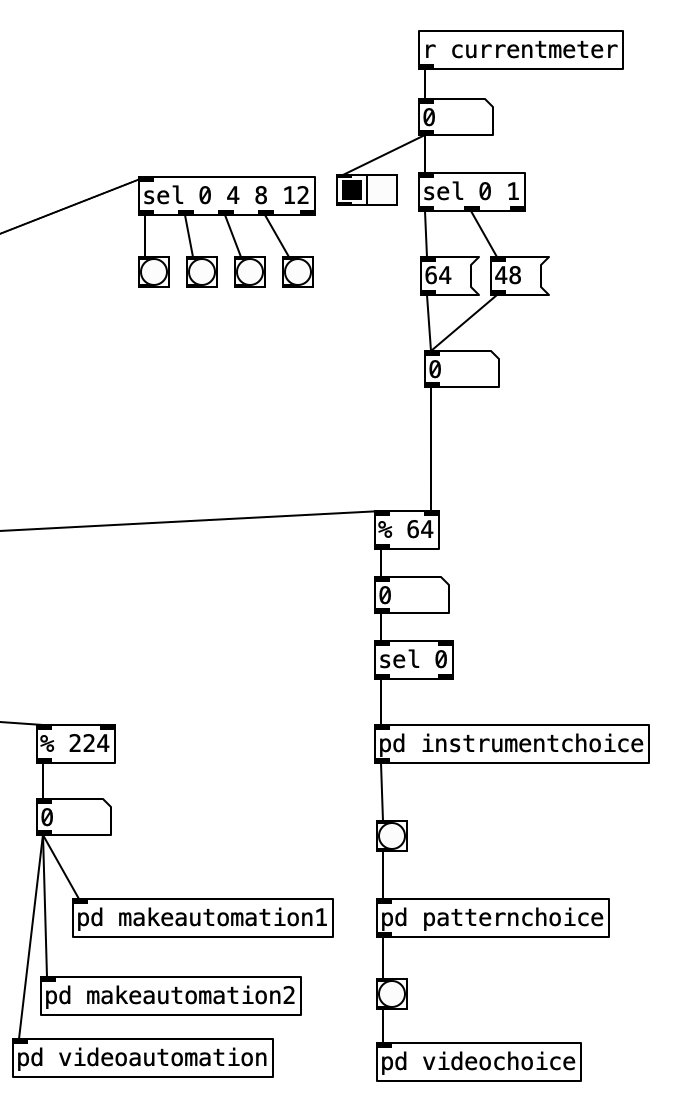
That being said, using an asymmetrical meter such as 7/8 creates a challenge for the visual metronome I added in experiment 5. Previously I was able to put a select statement, sel 0 4 8 12 that comes from the counter that tracks the sixteenth notes in a given meter. I could then connect each of the four leftmost outlets of that sel statement to a bang. Thus, each bang would activate in turn when you reach a downbeat (once every 4 sixteenth notes).
However, asymmetrical meters will not allow this to work. As the name suggests, in such meters the beat length is inconsistent. That is there are beats that are longer, and ones that are shorter. The most typical way to count 7/8 is to group the eighth notes with a group of 3 at the beginning, and to have two groups of 2 eighths at the end of the measure. This results in a long first beat (of 3 eighths or 6 sixteenth notes), followed by two short beats (of 2 eighths or 4 sixteenth notes).
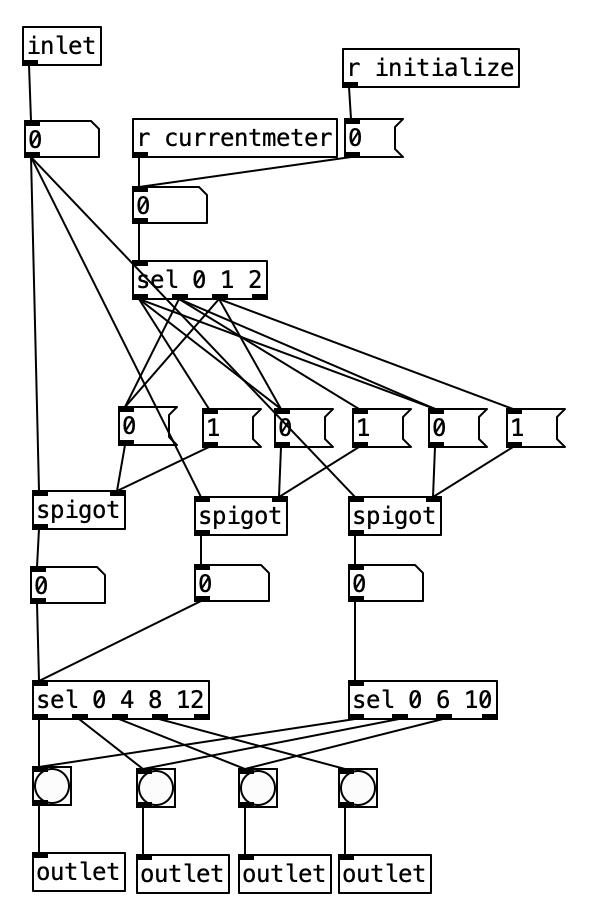
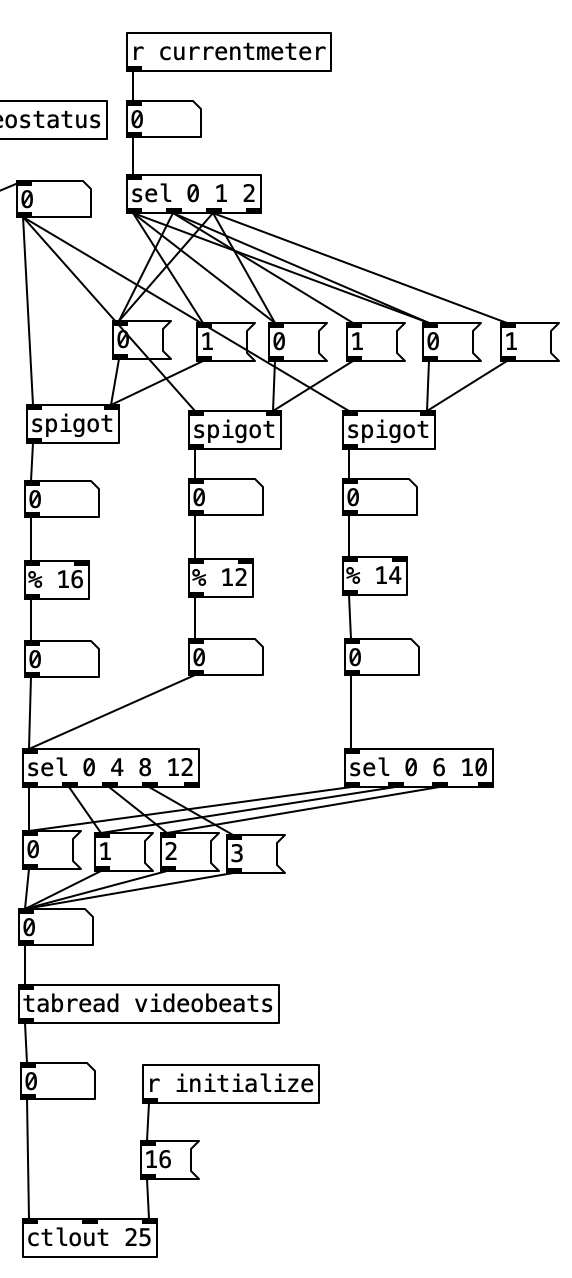
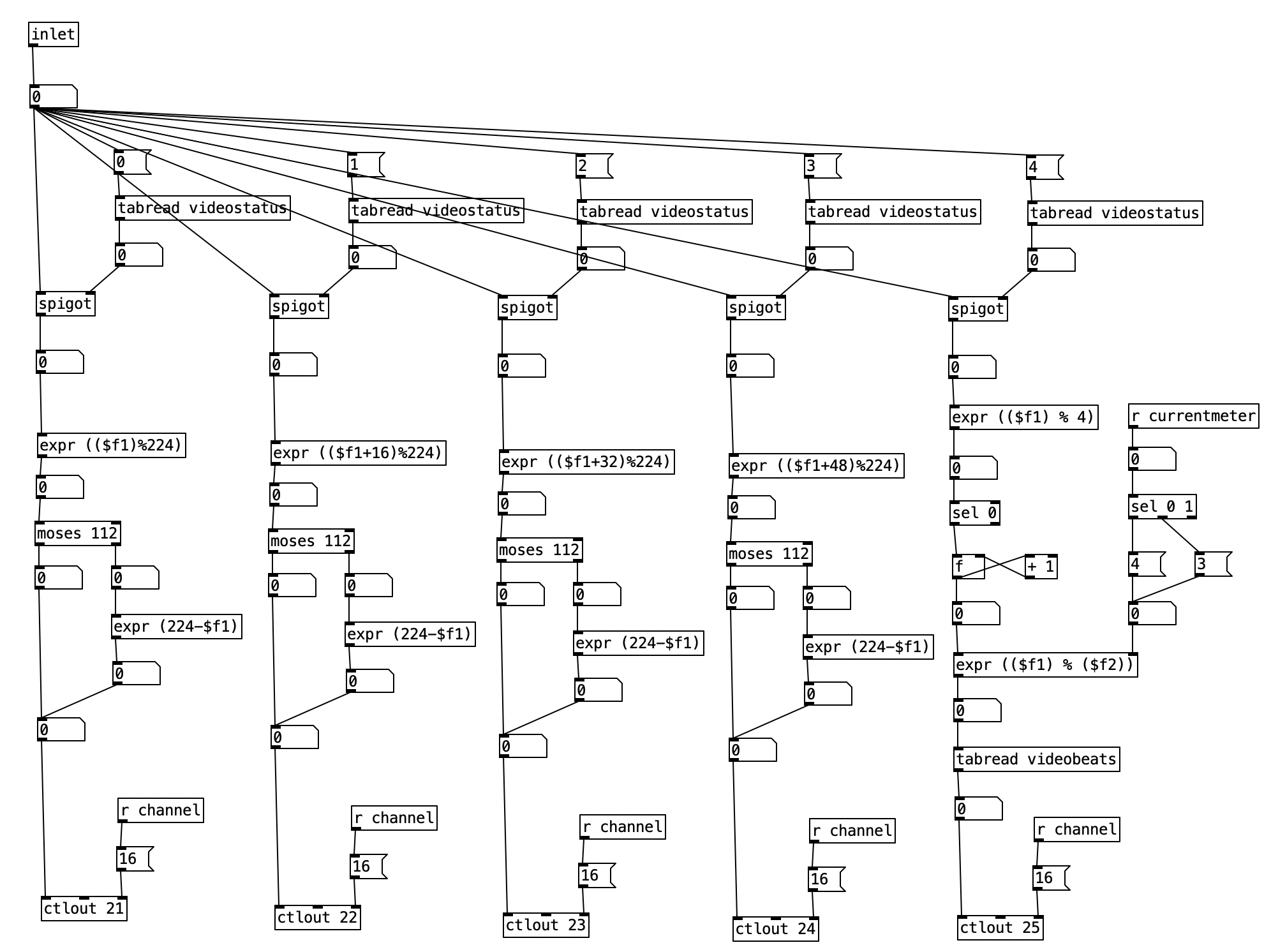
Accordingly, I created a new subroutine called pd count, which routes the sixteenth note count within the current measure based upon the current meter. Here we see that the value of currentmeter or a 0 sent by initialize is sent to a select statement that is used to turn on one of three spigots, and shut off the others. The stream is then sent to one of two select statements that identify when downbeats occur. Since both 4/4 an 3/4 use beats that are 4 sixteenth notes long, both of those meters can be sent to the same select statement. The other sel statement, sel 0 6 10, corresponds to 7/8. The second beat does not occur until the sixth sixteenth note, while the final downbeat occurs 4 sixteenth notes later at count 10.
One novel aspect of this subroutine is that it has multiple outlets. Each outlet is fed a bang. Each outlet of the subroutine is sent to a different bang, so the user can see the beats happen in real time. Note that this is next to a horizontal radio button, which displays the current meter. Thus, the user can use this to read both the meter, and which beat number is active.
I had to essentially recreate the code inside pd count inside of pd videoautomation in order to change the value of knob 5 of the EYESY on each downbeat. Here the output from the select statements are sent to messages of 0 through 3, which correspond to beats 1 through 4. These values are then used as indexes to access values stored in the array videobeats.
I did not progress with my work on the EYESY during this experiment, as I had intended to use the EYESY in conjunction with a webcam, but unfortunately I could not get the EYESY to recognize either of my two USB webcams. I did learn that you can send MIDI program changes to the EYESY to select which scene or program to make use of. However, I did not incorporate that knowledge into my work.
One interesting aspect of the EYESY related to program changes is that it runs every program loaded onto the EYESY simultaneously. This allows seamless changes from one algorithm to another in real time. There is no need for a new program to be loaded. This operational aspect of the EYESY requires the programs be written as efficiently as possible, and Critter and Guitari recommends loading no more than 10MB of program files onto the EYESY at any given time so the operation does not slow down.
As stated earlier, I was disappointed in the lack of expression of the Additive Odd Even patch when controlled by the WARBL. Again, I need to practice my EVI fingering. I am not quite use to reading the current meter and beat information off of the PureData screen, but with some practice, I think I can handle it. While the programming changes for adding 7/8 to the program that generates the accompaniment is not much of a conceptual leap from the work I did for Experiment 5, it is a decent musical step forward.
Next month I hope to make a basic sample instrument for the Organelle. I will likely add another meter to the algorithm that generates accompaniment. While I’m not quite sure what I’ll do with the EYESY, I do hope to move forward with my work on it.
It has been a busy month for me, so I’m afraid this experiment is not as challenging as it could be. I used the Organelle patch Constant Gardener to process sound from my lap steel guitar. This patch uses a phase vocoder, which allows the user to control speed and pitch of audio independently from each other. While I won’t go into great detail about what a phase vocoder is and how it works, it uses a fast Fourier transform algorithm to analyze an audio signal and to reinterpret it as time-frequency representation.
This process is dependent upon the Fourier analysis. The idea behind Fourier analysis is that complex functions can be represented as a sum of simpler functions. In audio this idea is used to separate complex audio signals into its constituent sine wave components. This idea is central to the concept of additive synthesis, which is based upon the idea that any sound, no matter how complex, can be represented by a number of sine wave elements that can be summed together. When we convert an audio signal to a time-frequency representation we get a three-dimensional analysis of the sound where one dimension is time, one dimension is frequency, and the third dimension is amplitude.
Not only can we use this data to resynthesize a sound, but in doing so, we can treat time and frequency separately. That is we can slow a sound down without making the pitch go lower. Likewise, we could raise the pitch of a sound without making the sound wave shorter.
Back to Constant Gardener. This patch uses knob 1 to control the speed (or time element) of the re-synthesis. Knob 2 controls the pitch of the resynthesis. The third knob controls the balance between the dry audio input to the Organelle with the processed (resynthesized) sound. The final knob controls how much reverb is added to the sound. The aux button (or foot pedal) is used to turn the phase vocoder resynthesis on or off.
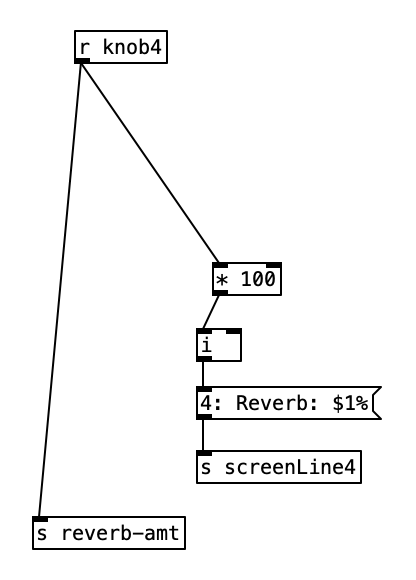
The phase vocoder part of the algorithm is sufficiently difficult such that I won’t attempt to go through it here, rather I will go through the reverb portion of the patch. As stated previously, knob four controls the balance between the dry (non-reverberated) and the reverberated sound. Thus value is then sent to the screen as a percentage, and is also sent to the variable reverb-amt using a number from 0 to 1 inclusive.
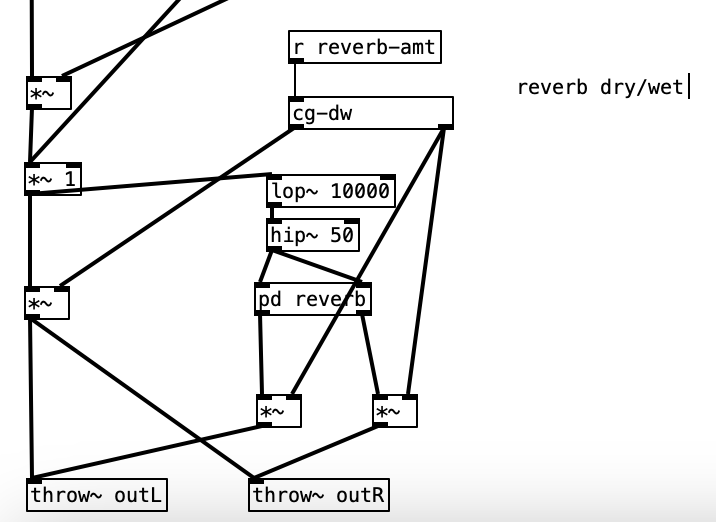
When the value of reverb-amt is recieved, it is sent to a subroutine called cg-dw. I’m not sure why the author of the patch used that name (perhaps cg stands for constant gardener), but this subroutine basically splits the signal in two, and modifies the value the will be returned out of the left outlet to be the inverse of the value of the right outlet (that is 1 – the reverb amount). Both values are passed through a low pass filter with cutoff frequency of 5 Hz, presumably to smooth out the signal.
The object lop~ 10000 receives its input from a chain that can be traced back to the input of the dry audio coming from the Organelle’s audio input. This object is a low pass filter, which means that the frequencies below the cutoff frequency, in this case 10,000 Hz, to pass through the filter, which in return attenuates the frequencies above the cutoff frequency. More specifically, lopis a one-pole, which means that the amount of attenuation is 6 dB per octave. A reduction of 6 dB effectively is half the power of the original. Thus, if the cutoff frequency of a low pass filter is set to 100 Hz, the power at 200 Hz (doubling a frequency raises the pitch an octave) is half of what it would normally be, and at 400 Hz, the power would be a quarter of what it would normally be.
In analog synthesis a two pole (12 dB / octave reduction) or a four pole (24 dB / octave) filter would be considered more desirable. Thus, a one pole filter can be thought of as a fairly gentle filter. This low pass filter is put in the signal chain to reduce the high frequency content to avoid aliasing. Aliasing is the creation of artifacts when a signal is not sampled frequently enough to faithfully represent a signal. Human beings can hear up to 20,000 Hz, but audio demands at least one positive value and one negative value to represent a sound wave. Thus, CD quality sound uses 44,100 samples per second. The Nyquist frequency, the frequency at which aliasing starts is half the sample rate. In the case of CD quality audio, that would be 22,050 Hz. Thus, our low pass filter reduces these frequencies by more than half.
The signal is then passed to the object hip~ 50. This object is a one-pole high pass filter. This type of filter attenuates the frequencies below the cutoff frequency (in this case 50 Hz). Human hearing goes down to about 20 Hz. Thus, the energy at this frequency would be attenuated by more than half. This filter is inserted into the chain to reduce thumps and low frequency noise.
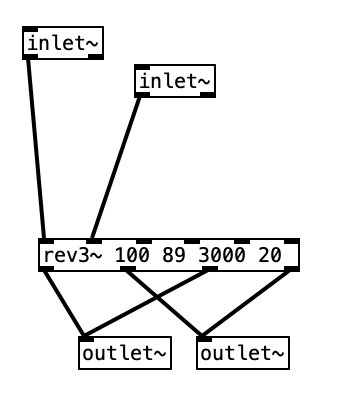
Finally we get to the reverb subroutine itself. The object that does most of the heavy lifting in this subroutine is rev~ 100 89 3000 20. This is a stereo input, four output reverb unit. Accordingly the first two inlets would be the left and right input. The other four inlets are covered by creation arguments (100 89 3000 20). These four values correspond to: output value, liveness, crossover frequency, and high frequency dampening. The output value is expressed in decibels. When expressed in this manner we can think of a change of 10 dB as doubling or halving the volume of a sound. We often consider the threshold of pain (audio so loud that it is physically painful to us) as starting around 120 dB. Thus, 100 dB, while considered to be loud, is 1/4 as loud as the threshold of pain. The liveness setting is really a feedback level (how much of the reverberated sound is fed back through the algorithm). A setting of 100 would yield reverb that would go on forever, while the setting 80 would give us short reverb. Accordingly, 89 gives us a moderate amount of reverb.
The last two values, cross over frequency and high frequency dampening work somewhat like a low pass filter. In the acoustic world low frequencies reverberate very effectively, while high frequencies tend to be absorbed by the environment. That is why a highly reverberant space like a cave or a cathedral has a dark sound to its reverb. In order to model this phenomenon, most reverb algorithms have an ability to attenuate high frequencies built into them. In this case 3,000 Hz is the frequency at which dampening begins. Here dampening is expressed as a percentage. Thus, a dampening of 0 would mean no dampening occurs, while 100 would mean that all of the frequencies about the crossover frequency are dampened. Accordingly, 20 seems like a moderate value. The outlets from pd reverbare then multiplied by the right outlet of cg-dw, applying the amount of reverb desired, and sent to the right and left outputs using throw~ outL and throw~ outR respectively.
For the EYESY I used the patch Mirror Grid Inverse – Trails. The EYESY’s five knobs are used to control: line width, line spacing, trails fade, foreground color, and background color. EYESY programming is accomplished in the language Python, and utilizes subroutines included in a library designed for creating video games called pygame.
An EYESY program is typically in four parts. The first part is where Python libraries are imported (pygame must be imported in any EYESY program). This particular program imports: os, pygame, math, and time. The second part is a setup function. This program uses the code def setup(screen, etc): pass to accomplish this. The third part is a draw function, which will be executed once for every frame of video. Accordingly, while this is where most of the magic happens, it should be written to be as lean as possible in order to run smoothly. Finally, the output should be routed to the screen.
In terms of the performance, I occasionally used knob 2 to change the pitch. I left reverb at 100%, and mix around 50% for the duration of the improvisation. I could have used the keyboard of the Organelle to play specific pitched versions of the audio input. Next month I hope to tackle additive synthesis, and perhaps use a webcam with the EYESY. Given that I’ve given a basic explanation of the first two parts of an EYESY program, in future months I hope to go through EYESY programs in greater detail.
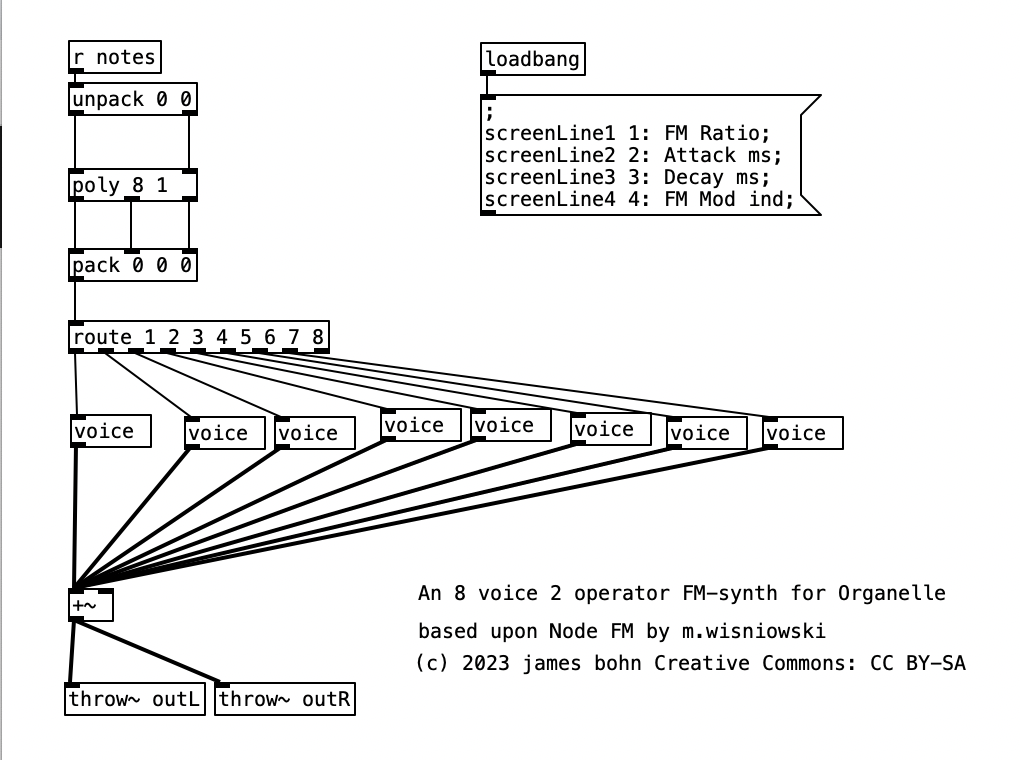
As was the case with Experiment 4, this month’s experiment has been a big step forward, even if the music may not seem to indicate an advance. This is due to the fact that this is the first significant Organelle patch that I’ve created, and that I’ve figured out how to connect the EYESY to wifi, allowing me to transfer files to and from the unit. The patch I created, 2opFM, is based upon Node FM by m.wisniowski.
As the name of the patch suggests it is a two operator FM synthesizer. For those who are unfamiliar with FM synthesis, one of the two operators is a carrier, which is an audible oscillator. The other operator is an oscillator that modulates the carrier. In its simplest form, we can think of FM synthesis as being like vibrato. One oscillator makes sound, while the other oscillator changes the pitch of the carrier. We can think of two basic controls that affect the nature of the vibrato, the speed (frequency) of the modulating oscillator, and the depth of modulation, that is how far away from the fundamental frequency does the pitch move.
What makes FM synthesis different from basic vibrato is that typically the modulating oscillator is operating at a frequency within the audio range, often at a frequency that is higher in pitch than that of the carrier. Thus, when operating at such a high frequency, the modulator doesn’t change the pitch of the carrier. Rather it functions to shape the waveform of the carrier. FM Synthesis is most often accomplished using sine waves. Accordingly, as one applies modulation we start to add harmonics, yielding more complex timbres.
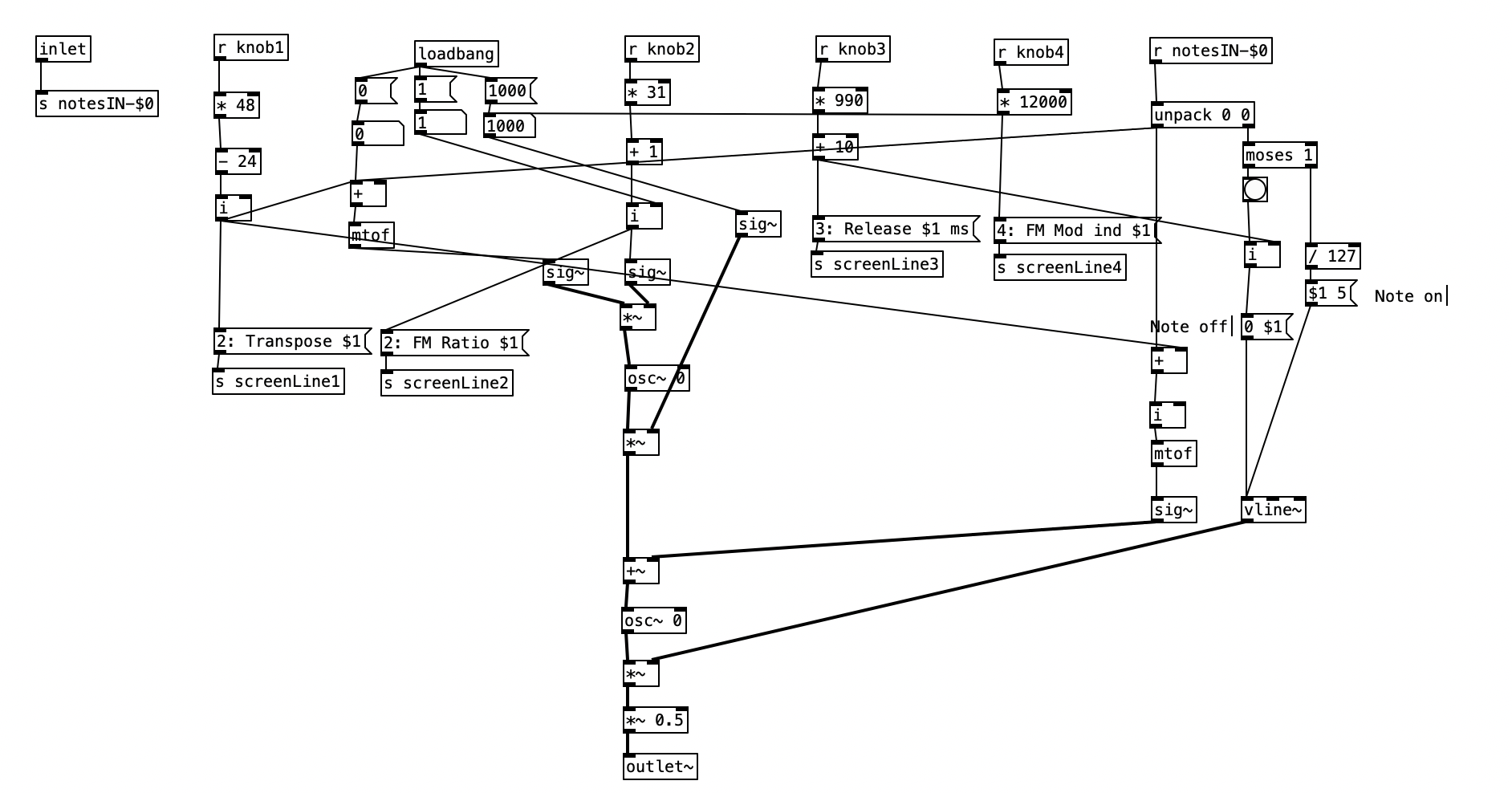
Going into detail about how FM synthesis shapes waveforms is well beyond the scope of this entry. However, it is worth noting that my application of FM synthesis here is very rudimentary. The four parameters controlled by the Organelle’s knobs are: transposition level, FM Ratio, release, and FM Mod index. Transposition is in semitones, allowing the user to transpose the instrument up to two octaves in either direction (up or down). FM Ratio only allows for integer values between 1 and 32. The fact that only integers are used here means that the result harmonic spectra will all conform to the harmonic series. Release refers to how long it will take a note to go from its operating volume to 0 after a note ends. The FM Mod index is how much modulation is applied to the carrier, with a higher index resulting in more harmonics added to a given waveform. I put this parameter on the leftmost knob, so that when I control the organelle via my wind controller, a WARBL, increases in air pressure will result in richer waveforms.
As can be seen in the screenshot of main.pd above, 2opFM is an eight voice synthesizer. Eight voice means that eight different notes can be played simultaneously when using a keyboard instrument. Each individual note is passed to the subroutine voice. Determining the frequency of the modulator involves three different parameters: the MIDI note number of the incoming pitch, the transposition level, and the FM ratio. We see the MIDI note number coming out of the left outlet of upack 0 0 on the right hand side, just below r notesIN-$0. For the carrier, we simply add this number to the transposition level, and then convert it to a frequency by using the object mtof, which stands for MIDI to frequency. This value is then, eventually passed to the carrier oscilator. For the modulator, we have to add the MIDI note number to the transposition level, convert it to a frequency, again using mtof, and multiplying this value by the FM Ratio.
In order to understand the flow of this algorithm, we first have to understand the difference between control signals and audio signals. Audio signals are exactly what they sound like. In order to have high quality sound audio signals are calculated at the sample rate, which is 44,100 samples per section by default. In Pure Data, calculations that happen at this rate are indicated by a tilde following the object name. In order to save on processor time, calculations that don’t have to happen so quickly are control signals, which are denoted by a lack of a tilde after the object name. These calculations typically happen once every 64 samples, so approximately 689 times per second.
Knowing the difference between audio signals and control signals, we can now introduce two other objects. The object sig~ converts a control signal into an audio signal. Likewise, i converts a float (decimal value) to an integer, by truncating the value towards zero, that is positive values are rounded down, while negative values are rounded up.
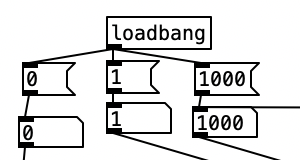
Keep in mind the loadbang portion of voice.pd is used to initialize the values. Here we see the transposition level set at zero, the FM ratio set to one, and the FM Mod index set to 1000. The values from the knobs come in as floats between 0 and 1 inclusive. Thus, typically in order to get useable values we have to perform mathematical operations to rescale them. Under knob 1, we see the transposition level multiplied by 48, and then we subtract 24 from that value. This will yield a value between -24 (two octaves down) and +24 (two octaves up). Under knob 2, we see the FM ratio multiplied by 31, and then we add one to this value, resulting in a value between 1 and 32 inclusive. Both of these values are converted to integers using i.
The scaled value of knob 1 (transposition level) is then added to the MIDI note number, and then turned into a frequency using mtof and converted to an audio signal using sig~. This is now the fundamental frequency of carrier oscillator. In order to get the frequency of the modulator, we need to multiply this value to the scaled value of knob 2. This frequency is then fed to the leftmost inlet of the modulating oscillator (osc~). The output of the modulating oscillator is then multiplied by the scaled output of knob 4 (0 to 12,000 inclusive), which is then in turn multiplied by the fundamental frequency of the carrier oscillator before being fed to the leftmost inlet of the carrier oscillator (osc~). While there is more going on in this subroutine, this explains how the core elements of FM synthesis are accomplished in this algorithm.
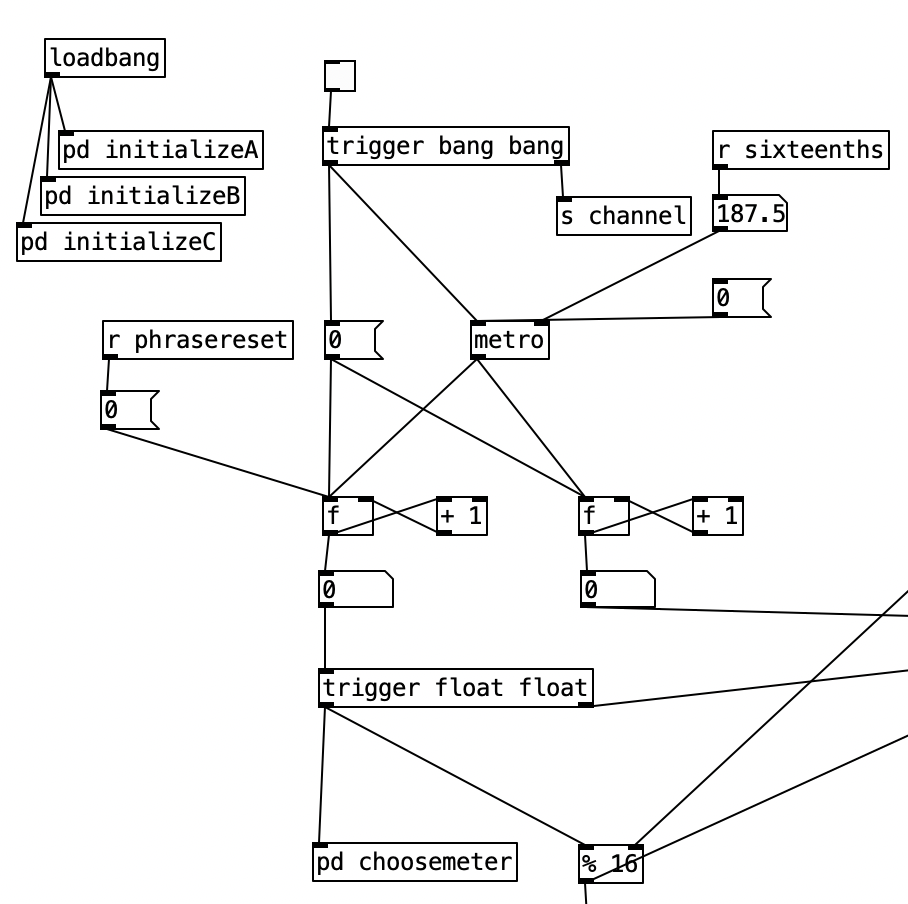
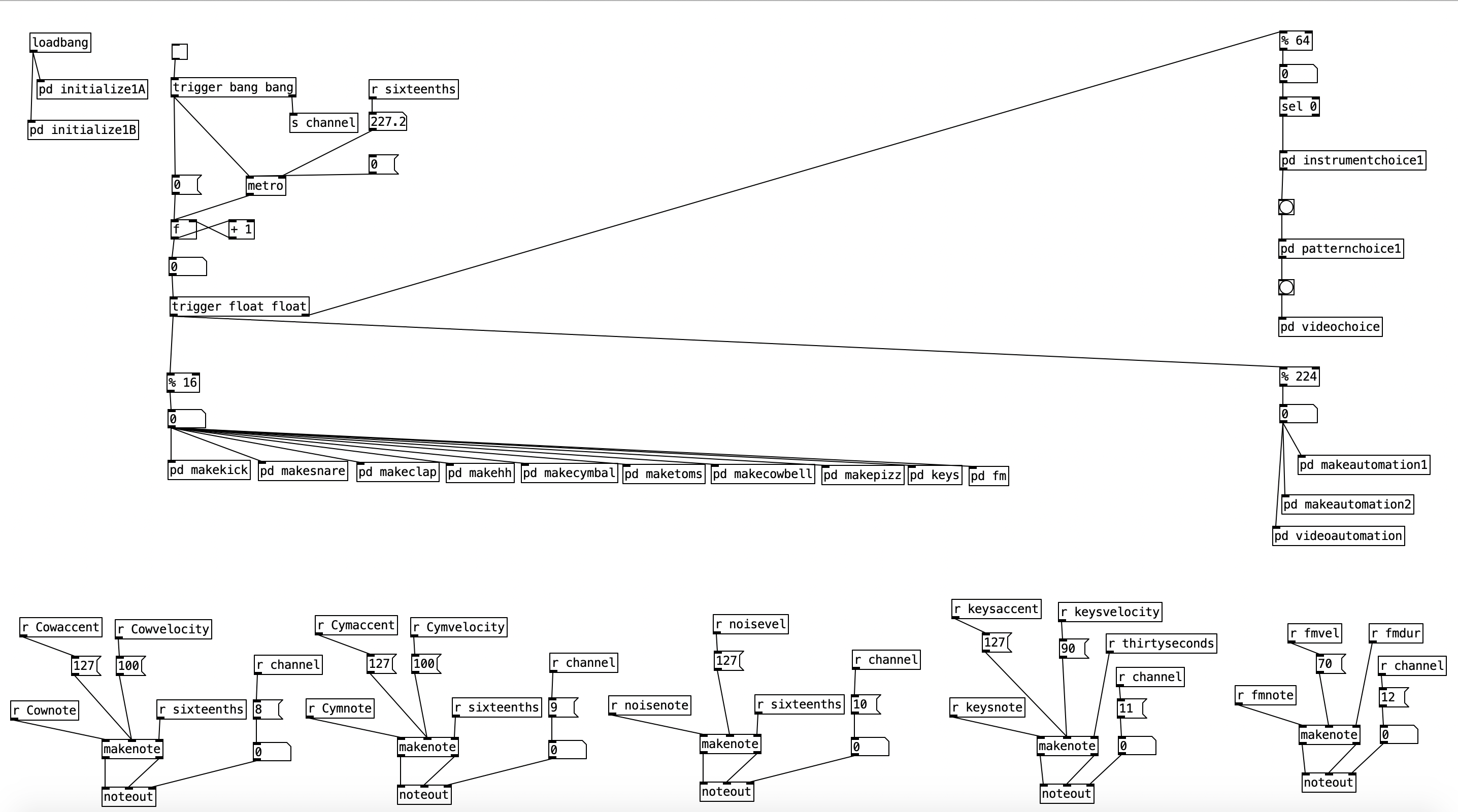
The algorithm that is used to generate the accompaniment is largely the same as the one used for Experiment 4 with a couple of changes. First, after completing Experiment 4 I realized I had to find a way to set the sixteenth note counter to zero every time the meter is changed. Otherwise, occasionally when changing from one meter to another there may be one or two extra beats. However, reseting the counter to zero ruins the subroutine that sends automation values. Thus, I had to use two counters, one that keeps counting without being reset (on the right) and one that gets reset every time the meter changes (on the left).
Initially I made a mistake by choosing the new meter at the beginning of a phrase. This caused a problem called a stack overflow. At the beginning of a phrase you’d chose a new meter, which would cause the phrase to reset, which would a new meter to be chosen, which then repeats in an endless loop. Thus, I had chose a new meter at the end of a phrase.
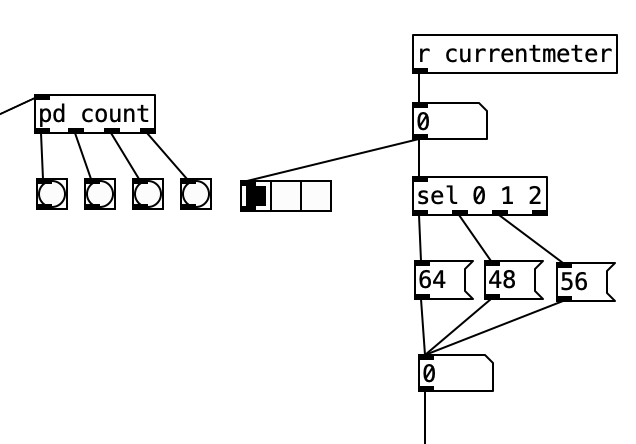
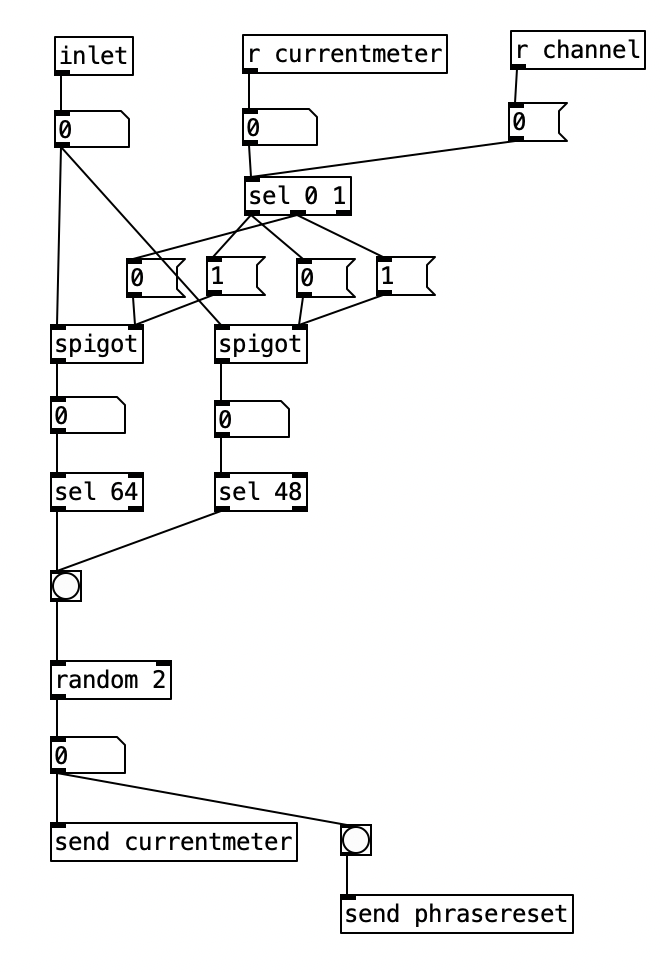
Inside pd choosemeter, we see the phrase counter being sent to two spigots. This spigots are turned on or off from depending on the value of currentmeter. The value 0 under r channel sets the meter for the first phrase to 4/4. Using the nomenclature of r channel is a bit confusing, as s channel is included in loadbang, and was simply included to initialize the MIDI channel numbers for the algorithm. In a future iteration of this program, I may retitle these values as s initializevalues and r initializevalues to make more sense.
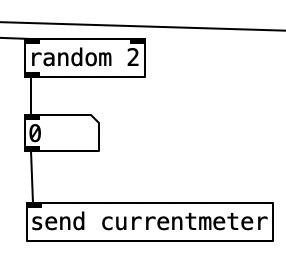
Underneath the two spigots, we see sel 64 and sel 48, This finds the end of the phrase when we are in 4/4 (64) or 3/4 (48). Originally I had used the values 63 and 47 as these would be the numbers of the last sixteenth note of each phrase. However, when I did that I found that the algorithm skipped the last sixteenth note of the phrase. Thus, by using 64 and 48 I actually am choosing the meter at the start of a phrase, but now reseting the counter to zero no longer triggers a recursive loop. Regardless, whenever either sel statement is triggered the next meter is chosen randomly, with zero corresponding to 4/4 and 1 corresponding to 3/4. This value is then sent to other parts of the algorithm using send currentmeter, and the phrase is reset by sending a bang to send phrasereset.
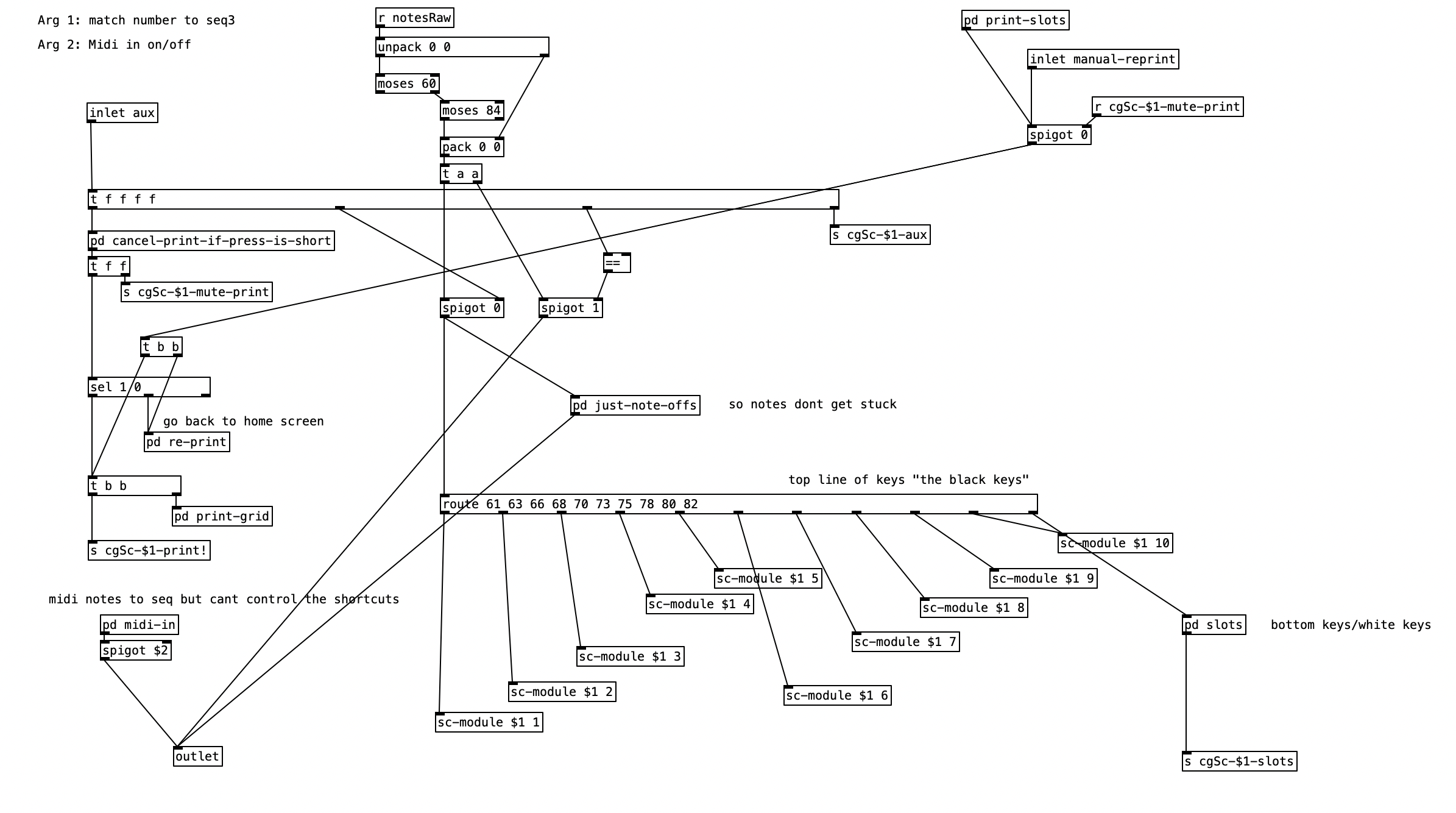
As previously noted, I figured out how to connect the EYESY to wifi, allowing me to transfer files two and from the unit. Amongst other things, this allows me to download new EYESY programs from patchstorage.com and add them to my EYESY. I downloaded a patch called Image Shadow Grid, which was developed by dudethedev. This algorithm randomly grabs images stored inside a directory, adds them to the screen, and manipulates them in the process.
I was able to customize this program without changing any of the code simply by changing out the images in the directory. I added images related to a live performance of a piece from my forthcoming album (as Darth Presley). However, up to this point I’d been using the EYESY to respond mainly to audio volume. Some algorithms, such as Image Shadow Grid, use triggers to incite changes in the video output. The EYESY has several trigger modes. I chose to use the MIDI note trigger mode. However, in order to trigger the unit I now have to send MIDI notes to the EYESY.
This constitute the other significant change to the algorithm that generates the accompaniment. I added a subroutine that sends notes to the EYESY. Since the pitch of the notes don’t matter, I simply send the number for middle C (60) to the unit. Otherwise the subroutine which determines whether a note should be sent to the EYESY functions just like those used to generate any rhythm, that is it selects between one of three rhythmic patterns for each of the two meters, each pattern of which is stored as an array.
As with last month, the significant weakness in this month’s experiment is my lack of practice on the WARBL. Likewise, it would have been useful if I had the opportunity to add a third meter to the algorithm that generates the accompaniment. The Organelle program 2opFM is not quite as expressive with the WARBL as it had been in experiment 2 and 4. Changes in the FM Mod Index aren’t as smooth as I had hoped they’d be. Perhaps if I were to expand the patch further, I’d want to add a third operator, and separate the FM Mod Index into two parts, one where you set the maximum level of the index, and another where you set the current level, so you can set it where the maximum breath pressure on the WARBL only yields a subtle amount of modulation.
In terms of the EYESY, I doubt I will begin writing programs for it next month, I may experiment with already existing algorithms that allow the EYESY to use a webcam. However, hopefully by October I can be hacking some Python code for the EYESY. My current plan is to experiment with some additive synthesis next month, so stay tuned.
While this month’s experiment may not seem musically much more advanced than Experiment 2, this month has actually been a significant step forward for me. I finished reading Organelle: How to Program Patches in Pure Data by Maurizio Di Berardino. More importantly, I finally got the WiFi working on my Organelle which allows me to transfer patches back and fourth between my laptop and the Organelle. I used that feature to transfer a patch called NESWave Synth by a user called blavatsky. This patch uses waveforms from the Nintendo Entertainment System, the Commodore 64, and others as a basis for a synthesizer. However, the synthesizer allows one to mix in some granular synthesis, add delay, add a a phasor, and other fancy features.
I made one minor tweak to NESWave Synth. In experiment 2 I used my WARBL wind controller to control the filter of Analog Style, I wanted to do the same with NESWave. On Analog Style, the resonance of the filter is on knob 3 and the cutoff frequency is on knob 4. On NESWave Synth, these to settings are reversed. So, I edited NESWave Synth so resonance is on knob 3 and cutoff frequency is on knob 4. I titled this new version of the patch NES EWI. This patch me to go from controlling Analog Style to NES EWI without changing the settings on my WARBL.
As NESWave Synth / NES EWI has a lot of other features / settings. During this experiment, I setup all the parameters of the synth the way I wanted, and didn’t make any changes in the patch as I performed, although again the breath pressure of the WARBL was controlling the filter cutoff frequency. Another user noted that NESWave Synth is complicated enough to warrant patch storage, although to the best of my knowledge no one has implemented such a feature yet.
The tweak I made to NESWave Synth is insignificant enough to not warrant coverage here. Accordingly I’ll go over changes I made to the PureData algorithm that generated the accompaniment for Experiment 2. Experiment 2 uses the meter 4/4 exclusively. I’ve been wanting to build an algorithm that randomly selects a musical meter at the beginning of each phrase. While the basic mechanics of this is easy, in order to add a second meter, I have to double the number of arrays that define the musical patterns.
In Experiment 4 I add the possibility of 3/4. Choosing between the two meters is simple. Inside the subroutine pd instrumentchoice I added a simple bit of code that randomly chooses between 0 and 1, and then sends that value out as currentmeter.
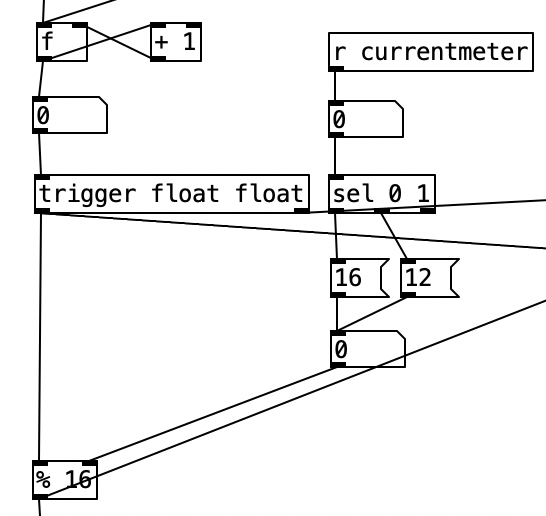
However, making this change causes three problems. The first is that the length of each measure now has change from 16 sixteenth notes to 12 sixteenth notes. That problem is solved in the main routine by adding an object that receives the value of currentmeter and uses that to select between an option that passes the number 16 or the number 12 to the right inlet of a mod operation on the global sixteenth note counter. This value will overwrite the initial value of 16 in the object % 16. As I write this, I realize I need to also reset the counter to 0 whenever I send a new meter so every phrase starts on beat 1. I can make that change in the next iteration of the algorithm.
The next problem is that I had to change the length of each phrase from 64 (4 x 16) for 4/4 to 48 (4 x 12) for 3/4. This is solved exactly the same way by passing the value of currentmeter to an object that selects either 64 or 48, and passes that value to the right inlet of a mod operation, overwriting the initial value of 64. Note that I also pass the value of currentmeter to a horizontal radio button so I can see what the current meter is. I can’t say that I actually used this in performance, but as I practice with this algorithm I should be able to get better at changing on the fly between a 4/4 feel and a 3/4 feel. Also, this should be much easier for me when I play an instrument I am more comfortable with than the EWI. I have also added a visual metronome using sel 0 4 8 12 each of which passes to a separate bang object. Doing this will cause each bang to flash on each successive beat. In future instances of this algorithm I may choose to just have it show where beat one is, as counting beats will become more complicated as I add asymetrical meters.
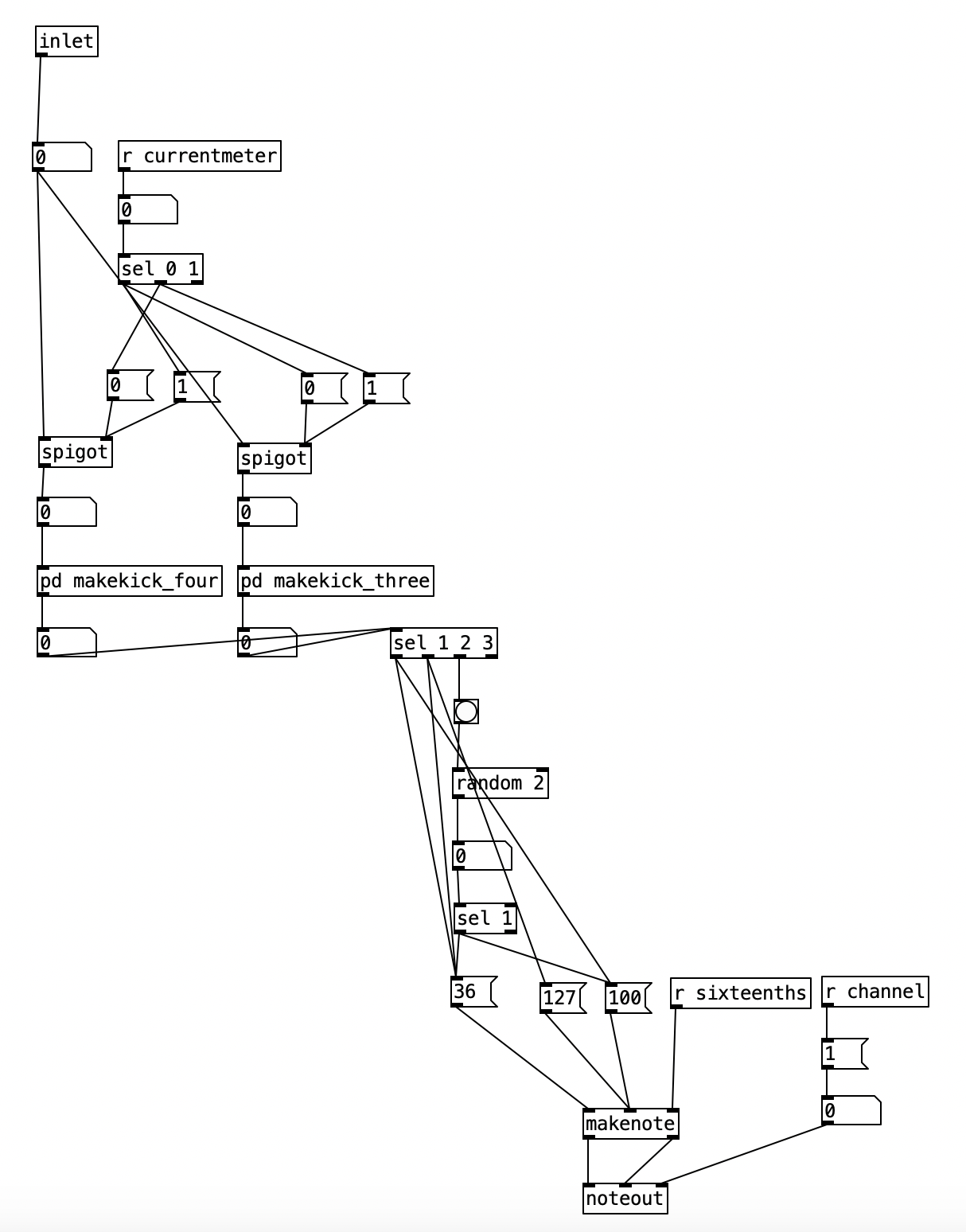
The final problem is that every subroutine that generates notes (pdmakekick, pd makesnare, pd makeclap, pd makehh, pd makecymbal pd maketoms pd makecowbell pd makepizz, pd makekeys, pd makefm) needs to be able to switch between using patterns for 4/4 and patterns for 3/4. While I made these changes to all 10 subroutines, it is the same process for each, so I’ll only show one version. Let’s investigate the pd makekick subroutine. The object inlet receives the counter for the current sixteenth note, modded to 16 or 12. This value is then passed to the left inlet of two different spigot objects. In PureData spigots pass the value of the left inlet to the outlet if the value at the right inlet is greater than zero. Thus, we can take the value of currentmeter to select which spigot gets turned on, and conversely, which one gets turned off, using the 0 and 1 message boxes.
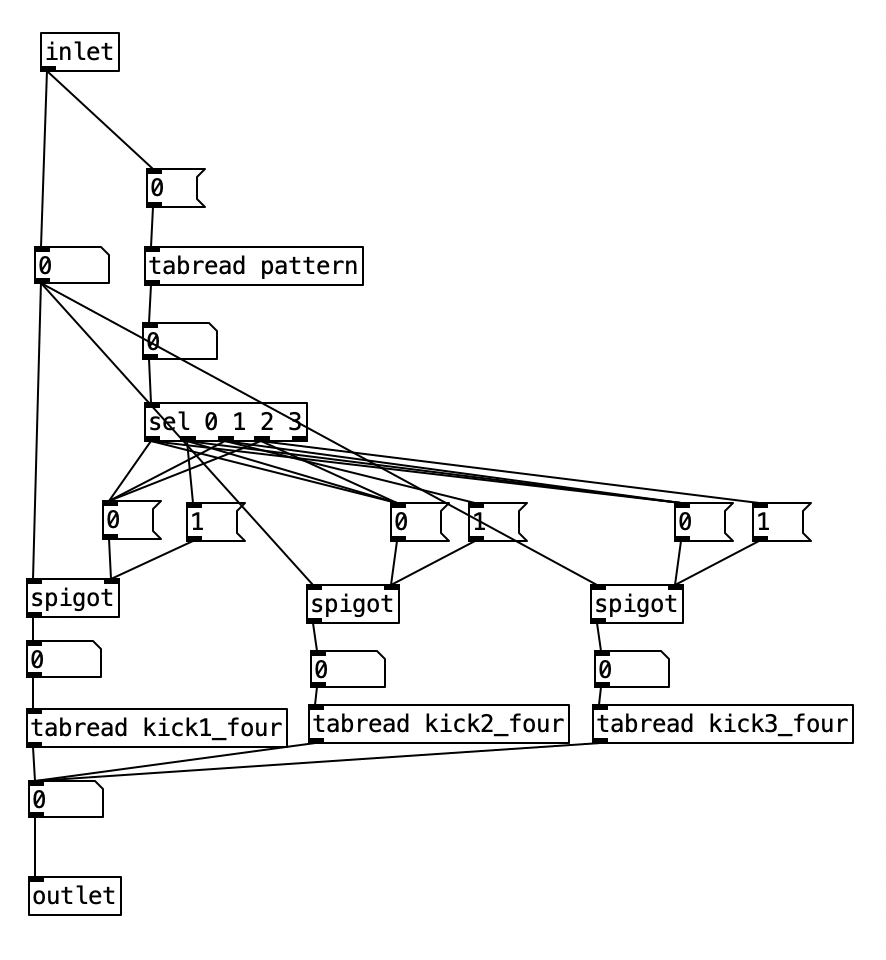
Now we know which meter is active, we will then pass to one of two subroutines which picks the current pattern. One of these subroutines pd makekick_four is for 4/4. The other, pd makekick_three is for 3/4. Both have essentially the same structure, so let’s look inside pd makekick_four. This subroutine uses the same structure as pd makekick. Again, the inlet receives the current value of the sixteenth note counter. Again, we use spigots to route this value, however, this time we use three spigotsas there are three different patterns that are possible. This routing is accomplished using the current value of pattern. The 0 position of this array stores the value for kick drum patterns. Technically speaking, there are four different patterns, 0, 1, 2, 3, with the value 0 meaning that there is no active pattern, resulting in no kick drum pattern. Again, a sel statement that passes to a series of 0 and 1 message boxes turn on and off the three spigots. The object tabread objects below read from three different patterns kick1_four, kick2_four, kick3_four. The value at this point is passed back out to the pd makekick subroutine. Since the possible values, 0, 1, 2, or 3, are the same whether the pattern is in 4/4 or 3/4, these values are then passed to the rest of the subroutine, which either makes an accented note, an unaccented, note, or calculates a 50% chance of an unaccented occuring. A fourth possibility, no note, happens when the value is 0. By not including 0 in the object sel 1 2 3 we insure no note will happen in that case.
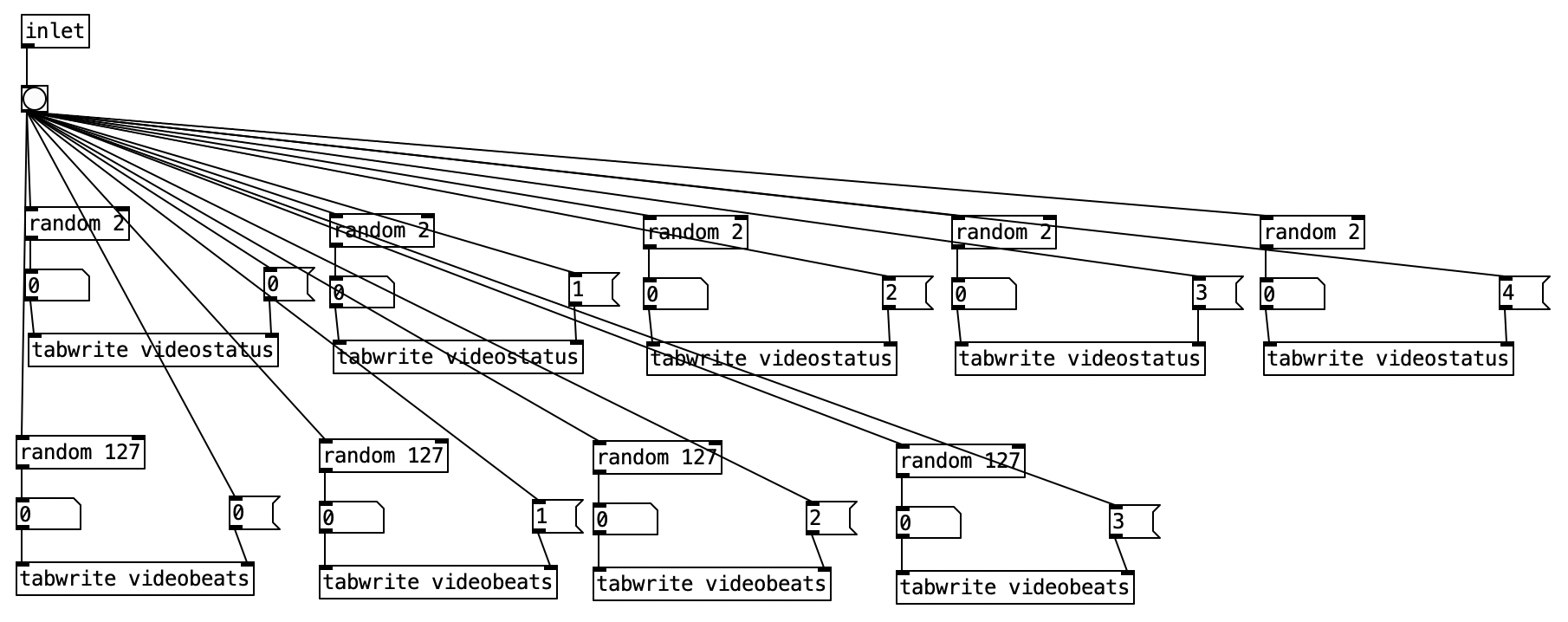
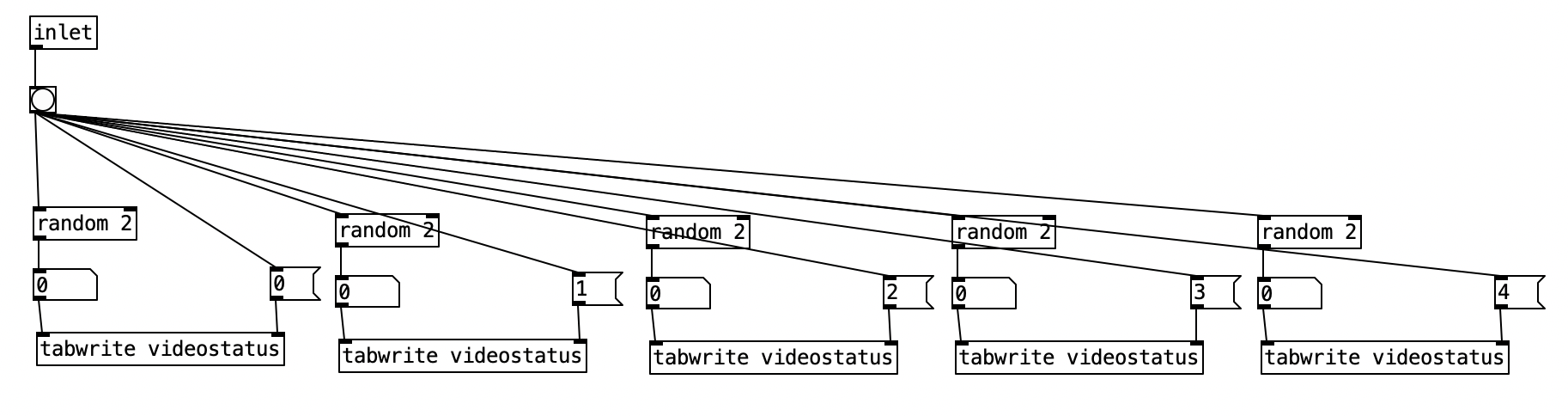
While I still haven’t looked into programming the EYESY, I did revise the PureData algorithm that controls the EYESY. In Experiment 2, all of the changes to the EYESY occur very gradually, resulting in slowly evolving imagery. In Experiment 4, I wanted to add some abrupt changes that occur on the beat. Most EYESY algorithms use knob 5 to control the background color. I figure that would be most apparent change possible, so in the subroutine pd videochoice I added code that would randomly choose four different colors (one for each potential beat), and to store them in an array called videobeats. Notice that each color is defined as a value between 0 and 126 (I realized while writing this, I could have used random 128) as we use MIDI to control the EYESY, and MIDI parameters have 128 different values.
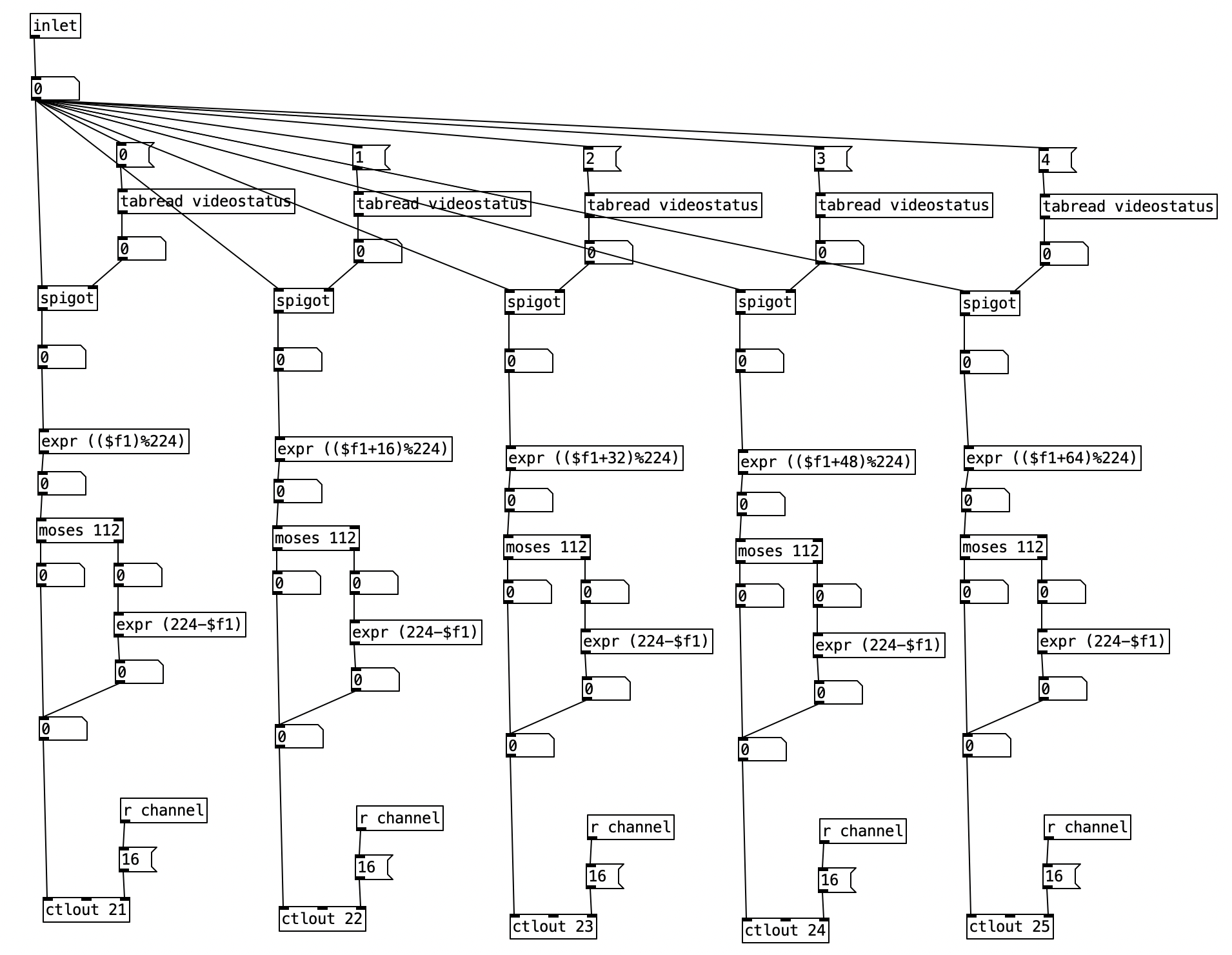
Now we have revise pd videoautomation to allow for this parameter control. The first four knobs use the same process that we used in Experiment 2. For the fifth knob, the 4 position in the array videostatus, we first check to see whether changes should happen for that parameter by passing the output of tabread videostatus to a spigot. When tabread videostatus returns a one, the spigot will turn on, otherwise, it will shut down. When the spigot is open, the current value of sixteenth note counter is passed to an object that mods the by 4. When this value is 0, we are on a beat. We then have a counter that keeps track of what the current beat number is. We then however, have to mod that either 4 for 4/4 or 3 for 3/4. The is accomplished using expr (($f1) % ($f2)). Here we pass the current meter to the right inlet, corresponding to $f2. We do thus using the value of currentmeter to select between a 4 and 3 message box. We can then get the color corresponding to the beat by returning the value of videobeats, and send that out to the EYESY using ctrlout 25 (25 being the controller number for the fifth knob of the EYESY).
In terms of the video, it is clear that I really need to practice my EVI fingerings. I am considering forcing the issue by booking a gig on the instrument to force me to practice more. I find that the filter control on Analog Style felt more expressive to me than the control on NES EWI. Though perhaps I need to recalibrate the breath control on the WARBL. I hope to do a more substantial hack next month, perhaps creating a two operator FM instrument. I also hope to connect the EYESY to WiFi so I can add more programs to it.
June has been busy for me. I’m behind where I wanted to be at this point in my research. This is due in part to not having a USB WiFi adapter to transfer files onto the Organelle and the EYESY. Accordingly, this month’s post will be light on programming, focusing on the Pure Data object route. I’ll be ordering one later this week, and will hopefully be able to take a significant step forward in July.
Accordingly, my third experiment in my project funded by Digital Innovation Lab at Stonehill College investigates the use of the preset patch Deterior (designed by Critter and Guitari). Deterior is an audio looper combined with audio effects in a feedback loop. In this experiment I run audio from a lap steel guitar.
The auxiliary key is used in conjunction with the black keys of the keyboard to select various functions. The lowest C# toggles loop recording on or off , the next D# stores the recording, the F# reverts to the most recent recording (removing any effects), the G# empties the loop, while A# toggles the input monitor. The upper five black keys of the instrument toggle on or off the five different effects that are available: noise (C#), clip (D#), silence (F#), pitch shift (G#), and filter (A#). The parameters of these effects cannot be changed from the Organelle, they can only be turned on or off. The routing of these auxiliary keys is accomplished through the subroutine shortcut.pd, using the statement route 61 63 66 68 70 73 75 78 80 82. Note that these numbers correspond to the MIDI note numbers for the black keys from C#4 to A#5.
A similar technique is used with the white keys of the instrument. These keys are used as storage slots for recorded loops, which can be recalled at any time once they are stored. This is initiated in pd slots, using route 60 62 64 65 67 69 71 72 74 76 77 79 81 83. These numbers correspond to the white keys from C4 to B5.
In this experiment I start using only filtering. Eventually I added silence, clipping, noise, and finally pitch shifting. Specifically, you can hear noise entering at 5:09. After adding all the effects in I stopped playing new audio, and instead focused on performing the knobs of the Organelle. Near the end of the experiment I start looping and layering a chord progression: Am, Dm, C#m, to Bm. When I introduce this progression I add one chord from this progression at a time.
In terms of the EYESY, I ran the recording through it so I would have my hands free to perform the settings. Again, I used a preset as I did not have a wireless USB connection to transfer files between my laptop and the EYESY. Hopefully next month I should be able to do deeper work with the EYESY.
Like Experiment 1, I had a lot of 60 cycle hum in the recording, which I tried to minimize by turning down the volume on the lap steel when I’m not recording sound. That process created it’s own distracting aspect of having the 60 cycle hum fade in and out in a repeating loop.
May has been a busy month for me. Thus, my second experiment in my project funded by Digital Innovation Lab at Stonehill College investigates the use of the preset patch Analog Style (designed by Critter and Guitari). To be specific, I am using a WARBL wind controller with EVI fingering to control the patch. I am using the breath control on the WARBL to control the cutoff frequency of Analog Style (using MIDI controller 24).
Due to the busyness of the end of the semester, this experiment features no original programming on the organelle. However, I did create a program in Pure Data to create accompaniment and drive the EYESY. To accompany the experiment, I used the H.E.A.P, the Housatonic Electronic Algorithmic Philharmonic. This a fun, frivolous name I’ve given to a small, battery powered synthesizer / sampler setup I’ve assembled for live performance. It consists of three synthesizers / samplers: a Volca Sample 2 (which provides 10 channels of late 1980s style lo fidelity digital sampling), a Volca Keys (which can be used as an analog monophonic or 3 note polyphonic synthesizer), and a Volca FM 2 (which is a clone of the 1980s classic, the Yamaha DX7, the best selling synthesizer of all time). I’ve also begun to think of the EYESY, as we’ll see later, as part of the H.E.A.P.
I won’t go into great detail about the program that generates the accompaniment for Experiment 2, as I have other blog posts that go into detail about various algorithms included in the program. Ultimately, the program is intended to generate relatively generic, but fairly usable R&B esque slow jams. The music is in common time using sixteenth notes. The portion of the program including and beneath % 16 (mod 16) ensures that the resulting music will have 16 pulses per measure. Likewise, the instrumentation and musical patterns change every four measures. This is enabled by the part of the program including and beneath % 64 (four measures of sixteenth notes adds up to 64).
The Volca Sample is being used to provide the drum beat, and some string pizzicato (see pd makepizz). The Volca Keys provides some synthesized bass patterns that run two measure loops. The Volca FM provides four chord, four note chord progressions that repeat every two measures. To create these chord progressions I used some music programming techniques that I’ve covered in a previous blog entry, though in this experiment I am use the brass friendly key of G minor.
One of the newer programming tricks I used in this program is an algorithm designed to drive the EYESY. While the EYESY generates hypnotic, interactive video animations, left to its own devices it can get a bit repetitive fairly quickly. In order to generate anything that seems even remotely dynamic some one needs to perform the EYESY by rotating its five knobs. This is an impossibility for any performing musician, save for a vocalist. Thankfully, we can do the equivalent of turning the knobs on the EYESY through MIDI using controllers 21 through 25.
The algorithm I’ve created to drive the EYESY is designed to make slow, evolving changes. To control these changes I’ve created a table called videostatus. It consists of five positions that contain a one or a zero to denote whether changes should be make or not made to a given knob during the current four measure phrase.
The subroutine pd videochoice is triggered at the beginning of every four measure phrase. It generates five different random numbers that are either a zero or a one. These results are then stored in the table videostatus.
The subroutine pd videoautomation updates the knob positions on the EYESY once every sixteenth note. It is passed the current sixteenth note number modded by the number 224, which corresponds to 14 measures of sixteenth notes. The subroutine contains five nearly identical columns, each of which corresponds to each of the five knobs on the EYESY. First the algorithm checks the current states of each of the five positions of videostatus table. When that value is one, that allows the current sixteenth note number to pass through the spigot. This value is passed through an expr statement that displaces the sixteenth note number. The column corresponding to knob one is not displaced, but each subsequent column is displaced by one measure (16 sixteenths), which is then modded to stay between 0 and 224. The statement moses 112 is used to determine whether we should be counting up to 112, or counting down to 0. This is accomplished by having numbers that are greater than 112 to pass through expr (224-$f1), which causes the result to get small as the input value is increased. The result of this is then passed to one of the five controller values (21-25) on MIDI channel 16 (the channel I’ve set my EYESY to).
Since I went over the mother patch in the previous experiment, I’ll start with going over main.pd for the Analog Style patch. We can see that knob one controls the tuning of the patch, while knob two creates an offset frequency for a second oscillator. The third knob sets the resonance of the low pass filter, while the fourth knob (the one I am controlling using the WARBL) sets the cutoff frequency of filter. To learn more about what low pass filters are, check out my blog entry on Low Pass Filters in LogicPro. However, to summarize briefly in relationship to the WARBL, when the amount of breath coming through is low, that in turn sets the cutoff frequency to be low as well, resulting in less sound (and only low frequency sound) to come out of the Organelle.
We can also see that this patch allows for sequencing when the aux button is down. However we will not go through how sequencing works today. We will however go into simple, which is the subroutine that creates the sound. We can see two oscillators, blsaw, in this subroutine that generate sawtooth waves. For more information on subtractive synthesis waveforms (including sawtooth waves), check out my blog entry on Subtractive Synthesis Waveforms in Logic Pro. One of those two blsaw oscillators is modified by the offset of knob two. The mixture of these two oscillators is passed to a low pass filter, moog~. This object also receives a center frequency to its center inlet, and a resonance value to its right most inlet. The outlet of this object is then attenuated slightly, *~ .75, before being sent to the subroutine’s outlet.
Again, I’ve found that the accompaniment generated by experiment.pd to be generic, but also fairly usable. It should be relatively easy to change the tempo, phrase length, or any number of musical patterns to create music that is stylistically different. Also, I enjoy slow evolving nature of EYESY generated video. I feel that turning on and off changes to various combinations of the five knobs add a degree of subtlety that aid in the dynamic nature of the video.
I am disappointed in my performance on the WARBL. I am still getting used to the EVI fingering on the instrument, so there are some very sour notes from time to time. However, I am very pleased with the range of the WARBL, as well as the subtle breath control the instrument provides. The fingering makes jumping octaves and fifths very easy. In future experiments I hope to get into hacking existing Organelle patches. I also plan to come up with variants of the videoautomation algorithm to create more sudden, less subtle changes to the EYESY’s settings.